本文章由 WyOJ Shojo 从洛谷专栏拉取,原发布时间为 2024-08-21 19:26:55
补题题号:U468736 - U468741
A.声渐悄
Subtask.1
博弈相关暴搜,或许需要子集枚举之类的东西,我没研究。
Subtask.3
考虑先手如何取最优,发现可以构造使得剩余的物品两两相邻,这样后手选择时每两个就必定会剩下一个,下一轮自己就可以选。按 $n$ 对 $3$ 取模的结果讨论发现答案为 $2\lfloor\frac n3\rfloor+[n \bmod 3\ne0]$。
最难做
我们先假设第一轮先手剩下一段长为 $3$ 的连续段 $a,b,c$ 不取。那么若 $b\ge a+c$,则直接取走 $b$ 一定更优;否则 $b<a+c$,后手一定会先取 $a+c$,这样自己下一次取时也会取走 $b$,第一轮就取走 $b$ 整体不劣。
所以先手可以在剩余连续段长度不超过 $2$ 的前提下达到最优,因此进行 DP,设 $f_i$ 表示先手第一轮取第 $i$ 个时,前 $i$ 个中先手能够获得的最大收益。转移为 $f_i=\max(f_{i-2},f_{i-3}+\min(a_{i-2},a_{i-1}))+a_i$。
意义即为中间留下一个则必为后手的,留两个的话后手会取较大的,自己可以获得较小的。答案为 $\max(f_n,f_{n-1})$,处理一下边界即可通过,时空复杂度 $O(n)$。
n=read();
for(int i=1;i<=n;i++) f[i]=a[i]=read();
for(int i=3;i<=n;i++) f[i]=max(f[i-2],f[i-3]+min(a[i-2],a[i-1]))+a[i];
print(max(f[n],f[n-1]));
B.乱红飞
Subtask.1
把 $2^n$ 个点全建出来,直接树形 DP。设 $f_u$ 表示以 $u$ 为根的子树中包含 $u$ 的连通块种类数,那么 $f_u=\prod_{v\in son_u}(f_v+1)$,也就是每个子树中选连通块的 $f_v$ 种方案和不选的 $1$ 种方案,乘法原理乘起来即可,时空复杂度 $O(2^d)$。代码我没写。
Subtask.2
发现对于满二叉树,同一层的点的子树结构完全相同,所以设 $g_i$ 表示第 $i$ 层点的 $f$ 值,由于都有两个儿子,有 $g_i=(g_{i+1}+1)^2$,答案为 $g_1$。代码我没写,但是离正解已经很近了。
最难做
注:这里 $s$ 字符串的下标为 $[0,d-1]$。
同 Subtask.2 一样,考虑把同一层的点按结构分类。这里按照该子树在第 $d$ 层的点的情况分类,设第 $0$ 类为第 $d$ 层无结点的点,第 $1$ 类为第 $d$ 层结点全满的点,第 $2$ 类为第 $d$ 层部分有结点的点。显然每层最多只有一个第 $2$ 类点。
那么设 $g_{i,j},j\in[0,2]$ 表示第 $i$ 层第 $j$ 种点的 $f$ 值,边界为 $g_{d,1}=1。$显然当 $j\le 1$ 时有 $g_{i,j}=(g_{i+1,j}+1)^2$,问题在于 $g_{i,2}$ 是怎么来的。
考虑算出第 $i$ 层的第 $2$ 类点在第 $d$ 层的点数,发现这个数量是 $s$ 的第 $i$ 位直到结尾所表示的二进制数。那么从后往前第一个 $1$ 处就是首次出现第 $2$ 类点的层数。
在出现第 $2$ 类点后,若 $s_i=1$,说明上一层的 $2$ 类点并上了一个 $1$ 类点,$s_i=0$ 说明并上了一个 $0$ 类点。因此有 $g_{i,2}=(g_{i+1,2}+1)(g_{i+1,s_i}+1)$,注意最终答案还要分讨一下。时空复杂度 $O(d)$。
cin>>d>>s,g[d][1]=1; bool tf=false;
for(int i=d-1;i>=1;i--)
{
g[i][0]=(g[i+1][0]+1)*(g[i+1][0]+1)%mod,g[i][1]=(g[i+1][1]+1)*(g[i+1][1]+1)%mod;
if(tf) g[i][2]=(g[i+1][2]+1)*(g[i+1][s[i]-'0']+1)%mod;
else if(s[i]-'0') tf=true,g[i][2]=(g[i+1][1]+1)*(g[i+1][0]+1)%mod;
}
if(s[0]=='1') cout<<g[1][1]<<'\n';
else if(tf) cout<<g[1][2]<<'\n';
else cout<<g[1][0]<<'\n';
C.恨千缕
Subtask.1.2
考虑暴力,也就是记录下每缕思绪是否存在以及出现的时间,每次查询时枚举所有思绪判断是否符合题意,时间复杂度 $O(nm)$。代码我没写。
Subtask.3
根据题面中的形式化题意,第 $j$ 天若第 $i$ 缕思绪存在,则其状态与 $(j-st_i)$ 对 $p=(x_i+y_i)$ 取模的值有关。同时由于 $st_i$ 是定值,所以本质上只与 $j$ 对 $p$ 取模的值有关。由于这个模数在本 Subtask 里很小,考虑开 $p^2$ 大小的数组存储答案。
设 $f_{p,i}$ 表示对 $p$ 取模值为 $i$ 的天数目前的答案。思绪出现时枚举 $[0,p-1]$ 作为 $i \bmod p$ 的结果,判断一下会对哪些余数造成贡献,存储在二维数组里,消失时把贡献撤销即可。查询只需要枚举 $p$,将所有 $f_p$ 的贡献求和,时间复杂度 $O(pm)$,空间复杂度 $O(p^2)$。可以参考 Subtask.4 后的代码。
最难做
发现每缕思绪本质上是向若干个区间贡献 $1$,所以考虑维护差分序列,在处理到第 $i$ 天时把前面的差分值加过来即可。但问题在于区间个数是 $O(\frac{m}{x_i+y_i})$ 级别的,可能会被卡到 $O(m^2)$,只能做 $(x_i+y_i)$ 较大的。
同时由于Subtask.3 中的做法只能做 $(x_i+y_i)$ 较小的,因此考虑按 $(x_i+y_i)$ 分治,超过 $B$ 的用差分做法,不超过 $B$ 的用 Subtask.3 中的做法,时间复杂度为 $O(mB+\frac{m^2}{B})$,分析一下可得 $B=\sqrt{m}$ 时最优,为 $O(m\sqrt{m})$。
考虑到 $O(mB)$ 全部跑满,而 $O(\frac{m^2}B)$ 完全跑不满,可以适当调低 $B$,但 std 仍使用了 $B=\sqrt m$。
n=read(),m=read(),B=sqrt(m\/2);
for(int i=1;i<=n;i++) x[i]=read(),y[i]=read();
for(int i=1;i<=m;i++)
{
int opt=read(),k=read(),tr=0,mo=(x[k]+y[k]);
if(mo<=B)
{
if(opt==1)
{
st[k]=i;
for(int j=0;j<mo;j++) if(((j-st[k])%mo+mo)%mo>=x[k]) f[mo][j]++;
}
else for(int j=0;j<mo;j++) if(((j-st[k])%mo+mo)%mo>=x[k]) f[mo][j]--;
}
else
{
if(opt==1)
{
st[k]=i;
for(int j=i;j+x[k]<=m;j+=mo)
{
s[j+x[k]]++;
if(j+mo<=m) s[j+mo]--;
}
}
else for(int j=(i-st[k])\/mo*mo+st[k];j+x[k]<=m;j+=mo)
{
if(j+x[k]>=i) s[j+x[k]]--;
else s[i]--;
if(j+mo<=m)
{
if(j+mo>=i) s[j+mo]++;
else s[i]++;
}
}
}
for(int j=2;j<=B;j++) tr+=f[j][i%j];
s[i]+=s[i-1],print(tr+s[i]),putchar('\n');
}
D.寄彩笺
Subtask.1
暴力枚举,分别枚举 $A,B$,对每个 $B$ 在每个 $A$ 中暴力查找个数。事实上这个点可以接受 $O(k^{n+m}nm)$ 的复杂度。代码我没写。
正解思路
考虑求每个 $B$ 在 $A$ 中贡献的次数,但也不能暴力枚举 $B$,所以要用某种东西给 $B$ 分类,使得同一类的 $B$ 对答案的贡献相同。
先考虑 $B$ 可重叠的贡献次数,这里长度 $len=m$,也就是在长为 $n$ 的 $A$ 中有 $(n-len+1)$ 种位置,钦定这些位置后其他位置随便填。所以长为 $len$ 的字符串可重叠的贡献次数为 $(n-len+1)k^{n-len}$。
接着考虑去掉重叠算多的贡献次数,发现前后两次会重叠当且仅当 $B$ 的一段前缀与 $B$ 的一段后缀相同,即若 $B=STS$,那么 $STSTS$ 出现时就会导致重叠。这里 $S,T$ 均为字符串,重叠部分 $S$ 即为 $B$ 的 border。
问题在于,若 border 长度超过 $m$ 的一半导致其本身有重叠,或 border 有多个,就无法使用唯一的 $STS$ 形式求解。然而,可以发现由于 border 完全相同,以上两种情况均会导致串内有三个或以上相同字符,而这在 $B$ 中是不会出现的,具体见下图:
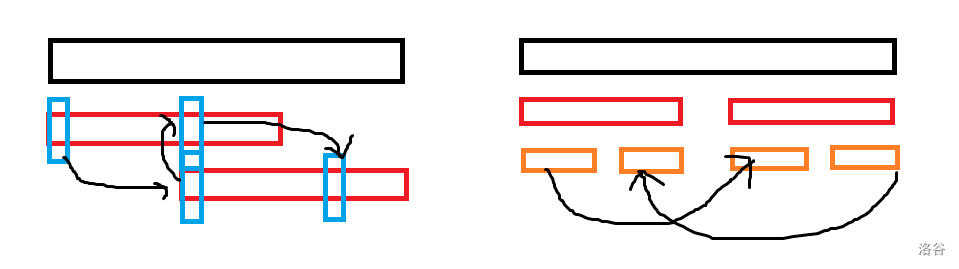
所以可以保证字符串没有或仅有一个 border,有则不会自己重叠,那么可以用唯一 border 的长度作为开头说的分类方式。枚举 border 的长度 $x$,从 $k$ 个字母中选出 $x$ 个作为 border $S$。用剩余的 $(k-x)$ 个字母,每个使用不超过两次构成 border 中间的串 $T$,乘法原理乘起来就是这种 $B$ 的总数量。
之后容斥求答案,即加上 $STS$ 的贡献,减去 $STSTS$ 的贡献,再加上 $STSTSTS$ 的贡献,以此类推直到 $STSTS\cdots TS$ 长度超过 $n$ 时停止。当然这里的贡献均可重叠,这样能保证最终贡献的量为不重叠出现的次数。
这里要枚举 $ST$ 的重复次数 $i$,但由于对于长度 $x$ 只会枚举约 $\frac nx$ 个次数,且 $x$ 不会取满 $[1,n]$,所以复杂度不超过调和级数的 $O(n\ln n)$。注意特判无解,并单独处理一下没有 border 的情况即可。代码里的 $p$ 数组记录的是 $k$ 的若干次方。
if(k*2<m||n<m)
{
cout<<0;
return 0;
}
res=sol(k,m)*p[n-m]%mod*(n-m+1)%mod; int now=1;
for(int x=1;x*2<=m;x++)
{
now=now*(k-x+1)%mod;
int ta=now*sol(k-x,m-2*x)%mod,w=1;
for(int i=2; ;i++)
{
w*=-1;
int len=m+(m-x)*(i-1);
if(len>n) break;
res=(res+ta*p[n-len]%mod*(n-len+1)%mod*w+mod)%mod;
}
}
cout<<res;
但是还有一处没有解决,即 Sol 函数解决用 $tk$ 种字母,每种字母使用不超过两次,组成的长为 $tm$ 的字符串种类数,其中 $tk\in [k-\lfloor\frac m2\rfloor,k],tm\in[m\bmod2,m]$,以下给出解法:
Subtask.2.3
考虑 DP,设 $f_{i,j}$ 表示长为 $i$ 的字符串,其中 $j$ 个字母使用了 $2$ 次,剩余 $(i-2j)$ 个字母使用了 $1$ 次的方案数。转移只需要讨论第 $i$ 个字符是否使用过,从 $f_{i-1}$ 转移过来即可,答案为 $\sum f_{tm,j}$。
由于每次的 $tk$ 不相同,每次都要重新用 $O(m^2)$ 的时间复杂度 DP,$O(m)$ 次询问的总时间复杂度为 $O(m^3)$。(由于跑不满,搬题人在原赛时写这个把 $m\le2000$ 全卡过去了,所以这里最后开了 $m\le3000$)
int sol(int k,int m)
{
f[0][0]=1; int res=0;
for(int i=1;i<=m;i++) for(int j=0;j*2<=i;j++)
{
f[i][j]=f[i-1][j]*(k-(i-1-j))%mod;
if((j-1)*2<=i-1) f[i][j]=(f[i][j]+f[i-1][j-1]*(i-1-2*(j-1))%mod)%mod;
}
for(int i=0;i*2<=m;i++) res=(res+f[m][i])%mod;
return res;
}
最难做
枚举字符串中出现 $2$ 次的字符数量 $i$,考虑组合计算方案数,结果为 $\binom {tk}i \times \frac{A_{tm}^{2i}}{2^i}\times A_{tk-i}^{tm-2i}$,前两项选出 $i$ 个字符出现两次并安排好位置,最后一项对每个剩下的位置依次不重复地选一个剩下的字符。
由于 $tk\ge k-\lfloor\frac m2\rfloor$,考虑预处理 $k$ 的下降幂,即 ${fk}i=\prod{j=k-i+1}^k j$,也就是从 $k$ 开始向下前 $i$ 个数的积,预处理 $m$ 个即可。之后自己展开式子就行,要注意每次的 $tk$ 不同,要把 $[tk+1,k]$ 这一段的积约掉。
p[0]=p2[0]=fr[0]=fk[0]=1;
for(int i=1;i<=n;i++) p[i]=p[i-1]*k%mod,p2[i]=p2[i-1]*2%mod;
for(int i=1;i<=m;i++) fr[i]=fr[i-1]*i%mod;
for(int i=1;i<=min(m,k);i++) fk[i]=fk[i-1]*(k-i+1)%mod;
int sol(int tk,int tm)
{
int res=0;
for(int i=0;i*2<=tm;i++) if(tm-i<=tk)
{
int ts=1,dt=k-tk,dk=inv(fk[dt]);
ts=ts*(fk[i+dt]*dk%mod)%mod*inv(fr[i])%mod;
ts=ts*(fr[tm]*inv(fr[tm-i*2])%mod*inv(p2[i])%mod)%mod;
ts=ts*(fk[tm-i+dt]*dk%mod*inv(fk[i+dt]*dk%mod)%mod)%mod;
res=(res+ts)%mod;
}
return res;
}
F.重霄九
Subtask.1
每次询问直接对子树内每个点分别 $O(n)$ 判断是否合法,时间复杂度 $O(qn^2)$。代码我没写。
Subtask.2-4
考虑类似线段树维护每个结点子树内的最大值,最小值和子树内合法结点的数量,修改时修改点权后将其到根路径上的所有结点依次重新维护,时间复杂度 $O(qd)$,$d$ 为树的最大深度。由于数据随机时二叉树的期望深度为 $O(\log n)$,$O(q\log n)$ 的时间复杂度可以通过。
struct tree
{
int lc[N],rc[N],a[N],s[N],mx[N],mn[N],fa[N];
bool f[N];
void pushup(int u)
{
int tl=lc[u],tr=rc[u];
mx[u]=max(max(mx[tl],mx[tr]),a[u]),mn[u]=min(min(mn[tl],mn[tr]),a[u]);
f[u]=(a[u]>=mx[tl]&&a[u]<=mn[tr]&&f[tl]&&f[tr]),s[u]=s[tl]+s[tr]+f[u];
}
void build(int u)
{
if(lc[u]) build(lc[u]);
if(rc[u]) build(rc[u]);
pushup(u);
}
void change(int u,int x)
{
a[u]=mx[u]=mn[u]=x;
while(u) pushup(u),u=fa[u];
}
}T;
signed main()
{
n=read(),Q=read();
for(int i=1;i<=n;i++) T.lc[i]=read(),T.rc[i]=read(),T.fa[T.lc[i]]=T.fa[T.rc[i]]=i;
for(int i=1;i<=n;i++) T.a[i]=T.mx[i]=T.mn[i]=read();
T.mx[0]=-inf,T.mn[0]=inf,T.s[0]=0,T.f[0]=1,T.build(1);
while(Q--)
{
int opt=read(),x=read();
if(opt==1)
{
int y=read();
T.change(x,y);
}
else print(T.s[x]),putchar('\n');
}
return 0;
}
最难做
发现树的形态不变,那么若子树是二叉搜索树,其中最大值和最小值的位置是确定的,分别为其最靠右和最靠左的结点。这里最靠某方向的点是指从根节点一直走该方向的儿子,直到这个儿子为空时所停的点。
同时若点 $i$ 是二叉搜索树,那么其左右子树一定均为二叉搜索树,所以相对应的最值位置是固定的。可以预处理出每个结点左子树最靠右的结点 $lx_i$ 和右子树最靠左的结点 $rx_i$。
根据定义,这个点合法只需要其左右儿子均合法且 $a_{lx_i}\le a_i\le a_{rx_i}$。同时由于每个点不可能同时是两个点的 $lx$,$rx$ 也一样,加上其自身的限制,总共不超过 $3$ 条,修改时重新判断一遍即可。
所以只要一棵子树内所有点都满足自身的限制,这棵子树就是二叉搜索树。考虑设 $f_i$ 表示点 $i$ 的限制是否不被满足,即满足则为 $0$,不满足则为 $1$,那么子树内所有点都满足限制当且仅当子树内 $f_i$ 的和为 $0$。
考虑维护这个子树和 $c_i$,那么每个 $f_i$ 都会给其到根的路径上点的 $c_i$ 贡献,而答案为子树内 $c_i=0$ 的个数,也就是子树内最小值为 $0$ 时的最小值个数。所以用树剖 + 线段树实现路径加,同时维护子树最小值及个数即可,时间复杂度 $O(q\log^2n)$。
#include<iostream>
#include<vector>
#define pii pair<int,int>
using namespace std;
const int N=2e5+10;
int n,q,a[N],lc[N],rc[N],lx[N],rx[N],rm[N],lm[N],f[N];
void ini(int u)
{
if(!u) return;
ini(lc[u]),ini(rc[u]);
rm[u]=rm[rc[u]],lm[u]=lm[lc[u]];\/\/lm 和 rm 分别表示最靠左和最靠右的结点
if(!rm[u]) rm[u]=u;
if(!lm[u]) lm[u]=u;
lx[u]=rm[lc[u]],rx[u]=lm[rc[u]];
}
vector <int> lim[N],edge[N];
int ct,siz[N],de[N],fa[N],son[N],id[N],top[N],aa[N],tw[N];
void dfs(int u,int fat)
{
fa[u]=fat,de[u]=de[fat]+1,siz[u]=1,tw[u]=f[u];
for(int v:edge[u])
{
dfs(v,u),siz[u]+=siz[v],tw[u]+=tw[v];
if(siz[son[u]]<siz[v]) son[u]=v;
}
}
void dfsb(int u,int to)
{
top[u]=to,id[u]=++ct,aa[ct]=tw[u];
if(!son[u]) return;
dfsb(son[u],to);
for(int v:edge[u]) if(v!=son[u]) dfsb(v,v);
}
struct sgmtt
{
int t=1,lc[N*2],rc[N*2],tag[N*2]; pii a[N*2]; \/\/最小值及个数
void pt(int u,int k) {a[u].first+=k,tag[u]+=k;}
void pushdown(int u) {if(tag[u]) pt(lc[u],tag[u]),pt(rc[u],tag[u]),tag[u]=0;}
void pushup(pii &u,pii tl,pii tr)
{
u.first=min(tl.first,tr.first),u.second=0;
if(tl.first==u.first) u.second+=tl.second;
if(tr.first==u.first) u.second+=tr.second;
}
void build(int u,int l,int r)
{
if(l==r) {a[u]={aa[l],1}; return;}
int mid=(l+r)\/2;
lc[u]=++t,build(t,l,mid);
rc[u]=++t,build(t,mid+1,r);
pushup(a[u],a[lc[u]],a[rc[u]]);
}
void add(int u,int l,int r,int ll,int rr,int k)
{
if(l>=ll&&r<=rr) {pt(u,k); return;}
int mid=(l+r)\/2; pushdown(u);
if(ll<=mid) add(lc[u],l,mid,ll,rr,k);
if(rr>mid) add(rc[u],mid+1,r,ll,rr,k);
pushup(a[u],a[lc[u]],a[rc[u]]);
}
pii check(int u,int l,int r,int ll,int rr)
{
if(l>=ll&&r<=rr) return a[u];
int mid=(l+r)\/2; pushdown(u);
if(rr<=mid) return check(lc[u],l,mid,ll,rr);
if(ll>mid) return check(rc[u],mid+1,r,ll,rr);
pii res;
pushup(res,check(lc[u],l,mid,ll,rr),check(rc[u],mid+1,r,ll,rr));
return res;
}
}T;
void addrt(int x,int k)
{
while(top[x]!=1) T.add(1,1,n,id[top[x]],id[x],k),x=fa[top[x]];
T.add(1,1,n,1,id[x],k);
}
signed main()
{
ios::sync_with_stdio(false),cin.tie(0),cout.tie(0);
cin>>n>>q;
for(int i=1;i<=n;i++) cin>>lc[i]>>rc[i];
ini(1),a[0]=-1,a[n+1]=n+1;
for(int i=1;i<=n;i++) cin>>a[i],lim[i].push_back(i);
for(int i=1;i<=n;i++)
{
if(lc[i]) edge[i].push_back(lc[i]);
if(rc[i]) edge[i].push_back(rc[i]);
if(lx[i]) lim[lx[i]].push_back(i);
if(rx[i]) lim[rx[i]].push_back(i);
else rx[i]=n+1;
f[i]=!(a[lx[i]]<=a[i]&&a[rx[i]]>=a[i]);
}
dfs(1,0),dfsb(1,1),T.build(1,1,n);
while(q--)
{
int opt,x; cin>>opt>>x;
if(opt==2)
{
pii te=T.check(1,1,n,id[x],id[x]+siz[x]-1);
cout<<(te.first?0:te.second)<<'\n';
}
else
{
int y; cin>>y;
for(int i:lim[x]) addrt(i,-f[i]);
a[x]=y;
for(int i:lim[x]) f[i]=!(a[lx[i]]<=a[i]&&a[rx[i]]>=a[i]),addrt(i,f[i]);
}
}
return 0;
}
Ex.凭阑意
以下设 $a_i$ 的值域为 $V$。
Subtask.1.2
发现答案上界为 $\max a_i$,因为 $p=\max a_i$ 时,最大值变为 $0$,其他值不变,一定不会有相同元素。所以从小到大枚举 $p$,$O(n)$ 用桶判重即可,总时间复杂度 $O(Vn)$。代码我没写。
Subtask.3
转换条件,发现 $a_i\equiv a_j\bmod p$ 等价于 $p\mid (a_i-a_j)$,也就是说若存在 $\left|a_i-a_j\right|$ 是 $p$ 的倍数,则 $p$ 不合法。所以可以 $O(n^2)$ 枚举差值,再从小到大找倍数中没有差值的数。由于枚举倍数的时间复杂度为 $O(V\ln V)$,总时间复杂度为 $O(n^2+V\ln V)$。
for(int i=1;i<=n;i++) for(int j=i+1;j<=n;j++) if(a[j]>a[i]) f[a[j]-a[i]]=1;
for(int i=1;i<=V;i++)
{
for(int j=i*2;j<=V;j+=i)
{
f[i]|=f[j];
if(f[i]) break;
}
if(!f[i]) {print(i);break;}
}
Subtask.4
同 Subtask.3 思路相同,从小到大判断数是否能作为 $p$,同样枚举倍数来判断,时间复杂度 $O(V\ln V)$。现在的问题在于如何快速判断 $a$ 中是否存在 $x$ 作为差值。
考虑使用 bitset 优化,开值域大小的 bitset $B$ 记录每个值是否存在,那么存在 $x$ 作为差值当且仅当 $B$ 左移或右移 $x$ 位后按位与 $B$ 的结果中有 $1$。
再开个数组记忆化,保证每个 $x$ 只 check 一遍,时间复杂度 $O(\frac{V^2}w)$,总时间复杂度 $O(V\ln V+\frac{V^2}w)$。这也是最后一个 Subtask 值域缩小到 $10^5$ 的原因,得到满分需要把后两个 Subtask 拼起来。
bitset <M> bs;
bool vis[N],ma[N];
bool check(int x)
{
if(!vis[x])
{
vis[x]=1;
if(((bs>>x)&bs).count()) ma[x]=1;
else ma[x]=0;
}
return ma[x];
}
void solb()
{
for(int i=1;i<=n;i++) bs[a[i]]=1;
for(int i=2;i<=V\/10;i++)\/\/ V\/10 即为本 Subtask 的值域 10^5
{
bool tf=true;
for(int j=i;j<=V\/10;j+=i) if(check(j)) {tf=false; break;}
if(tf) {print(i); break;}
}
}