题目顺序是:
T1 T2 T3 T4 T5
368 369 370 365 364
题目顺序是:
T1 T2 T3 T4 T5
368 369 370 365 364
import asyncio
import time
import websockets
import aiohttp
import traceback
import json
import random
import base64
import aiosqlite
import re
import os
wsserver = 'ws://172.17.0.2:3001/'
ws = None
commands = dict ()
trusted_senders = [ 2681243014 ]
confirm_queue = dict ()
reply_queue = dict ()
file_queue = dict ()
sqlconn = None
GROUP_ID = 1061173220
def wyoj_enable (qq, name):
if re.match (r'^([A-Za-z0-9_]*)$', name) is None:
raise Exception ('wyoj_enable: Invalid username; possible injection')
os.system (f"sudo docker exec uoj-db mysql -proot app_uoj233 -e \"update user_info set usergroup = 'U', qq = '{qq}' where username = '{name}'\"")
def wyoj_disable (name):
if re.match (r'^([A-Za-z0-9_]*)$', name) is None:
raise Exception ('wyoj_disable: Invalid username; possible injection')
os.system (f"sudo docker exec uoj-db mysql -proot app_uoj233 -e \"update user_info set usergroup = 'B' where username = '{name}'\"")
def wyoj_adminize (name):
if re.match (r'^([A-Za-z0-9_]*)$', name) is None:
raise Exception ('wyoj_adminize: Invalid username; possible injection')
os.system (f"sudo docker exec uoj-db mysql -proot app_uoj233 -e \"update user_info set usergroup = 'S' where username = '{name}'\"")
# 暂时不考虑嵌套。
def wyoj_deadminize (name):
if re.match (r'^([A-Za-z0-9_]*)$', name) is None:
raise Exception ('wyoj_deadminize: Invalid username; possible injection')
os.system (f"sudo docker exec uoj-db mysql -proot app_uoj233 -e \"update user_info set usergroup = 'U' where username = '{name}'\"")
def wyoj_admins ():
return os.popen ("sudo docker exec uoj-db mysql -proot app_uoj233 -e \"select username from user_info where usergroup = 'S';\"").read ()
def wyoj_banned ():
return os.popen ("sudo docker exec uoj-db mysql -proot app_uoj233 -e \"select username from user_info where usergroup = 'B';\"").read ()
async def db_insert_bind (uid, name):
cursor = await sqlconn.cursor ()
await cursor.execute (f'insert into binds (qq, name) values (\'{uid}\', \'{name}\')');
await sqlconn.commit ()
await cursor.close ()
async def db_delete_bind (name):
cursor = await sqlconn.cursor ()
await cursor.execute (f'delete from binds where name = \'{name}\'');
await sqlconn.commit ()
await cursor.close ()
async def db_query_by_id (uid):
cursor = await sqlconn.cursor ()
await cursor.execute (f'select qq, name from binds where qq = \'{uid}\'')
res = await cursor.fetchall ()
await cursor.close ()
return res
async def db_query_by_name (name):
cursor = await sqlconn.cursor ()
await cursor.execute (f'select qq, name from binds where name = \'{name}\'')
res = await cursor.fetchall ()
await cursor.close ()
if len (res) > 1:
raise Exception ('重复绑定')
if len (res) == 1:
return res[0]
return None
async def db_query_binds ():
cursor = await sqlconn.cursor ()
await cursor.execute (f'select qq, name from binds order by qq')
res = await cursor.fetchall ()
await cursor.close ()
return res
async def db_count_bound (qq):
cursor = await sqlconn.cursor ()
await cursor.execute (f'select count (*) from binds where qq = \'{qq}\'')
res = await cursor.fetchone ()
await cursor.close ()
return res[0]
async def db_check_bound (name):
cursor = await sqlconn.cursor ()
await cursor.execute (f'select count (*) from binds where name = \'{name}\'')
res = await cursor.fetchone ()
await cursor.close ()
return res[0] > 0
async def db_banned (qq):
cursor = await sqlconn.cursor ()
await cursor.execute (f'select count (*) from bans where qq = \'{qq}\'')
res = await cursor.fetchone ()
await cursor.close ()
return res[0] > 0
async def db_banned_all ():
cursor = await sqlconn.cursor ()
await cursor.execute (f'select qq from bans')
res = await cursor.fetchall ()
await cursor.close ()
return res
async def db_ban (qq):
cursor = await sqlconn.cursor ()
await cursor.execute (f'insert into bans (qq) values (\'{qq}\')');
await sqlconn.commit ()
await cursor.close ()
async def db_unban (qq):
cursor = await sqlconn.cursor ()
await cursor.execute (f'delete from bans where qq = \'{qq}\'');
await sqlconn.commit ()
await cursor.close ()
refpatt = re.compile (r'\[CQ:reply,id=([0-9]*)\]')
atpatt = re.compile (r'\[CQ:at,qq=([0-9]*)\]')
class MessageMeta:
def __init__ (self, data):
s = data['raw_message']
self.data = data
self.uid = data['user_id']
self.gid = data['group_id']
self.msgid = data['message_id']
self.refs = re.findall (refpatt, s)
self.ats = re.findall (atpatt, s)
i = 0
flag = False
while i < len (s) and (flag or s[i] == '['):
flag |= s[i] == '['
flag &= s[i] != ']'
i += 1
while i < len (s) and s[i] == ' ':
i += 1
self.msg = s[i:]
self.cmd = self.msg.split ()
async def reply_msg (meta, msg):
return await ws.send (json.dumps ({
'action': 'send_group_msg',
'params': {
'group_id': meta.gid,
'message': [ { 'type': 'reply', 'data': { 'id': meta.msgid } },
{ 'type': 'text', 'data': { 'text': msg } } ]}}))
def download_dir (s):
return f'./download/{s}'
FILE_KEEP_MIN = 60
REPOTER_GAP = 5
CHUNK_SIZE = 1048576 * 16
async def receive_file (meta, data):
size = int (data['message'][0]['data']['file_size'])
url = data['message'][0]['data']['url']
name = data['message'][0]['data']['file']
if not name.endswith ('.zip'):
return await reply_msg (meta, f'识别到非 ZIP 格式文件,未下载')
await reply_msg (meta, f'识别到 ZIP 格式文件,大小 %.3lf MB 正在下载' % (size / 1048576))
start_time = time.time ()
rx = 0
finished = False
async def reporter ():
while not finished:
duration = time.time () - start_time
if rx != 0:
await reply_msg (meta, f'已下载 %.3lf MB = %.3lf MB/s = %.3lf Mbps, ETA %.2lf 秒'
% (rx / 1048576, rx / 1048576 / duration, rx * 8 / 1048576 / duration, duration / rx * size))
await asyncio.sleep (REPOTER_GAP)
asyncio.create_task (reporter ())
async with aiohttp.ClientSession () as sess:
async with sess.get (url) as resp:
if resp.status != 200:
await reply_msg (meta, f'请求 {url} 失败。HTTP 状态码 {resp.status}')
filename = download_dir (str (meta.msgid))
with open (filename, 'wb') as f:
async for chunk in resp.content.iter_chunked (CHUNK_SIZE):
f.write (chunk)
rx += len (chunk)
duration = time.time () - start_time
finished = True
await reply_msg (meta, f'已成功下存到 {filename},耗时 %.3lf 秒,合 %.3lf MB/s = %.3lf Mbps\n将在 {FILE_KEEP_MIN} 分钟后删除。'
% (duration, size / duration / 1048576, size * 8 / 1048576 / duration))
await asyncio.sleep (FILE_KEEP_MIN * 60)
await reply_msg (meta, f'到时,删除文件 {filename}')
os.system (f'rm {download_dir (filename)}')
def random_token ():
s = ''
for i in range (16):
s += random.choice ('abcdefghijklmnopqrstuvwxyz')
return s
def gen_confirm_token (meta):
while True:
s = str (meta.uid) + random_token ()
s = base64.b64encode (s.encode ('utf-8')).decode ('utf-8')
if s not in confirm_queue:
return s
CONFIRM_TIMEOUT = 60
async def confirm (meta, msg):
token = gen_confirm_token (meta)
future = asyncio.Future ()
confirm_queue[token] = future
await reply_msg (meta, f'{msg}\n{CONFIRM_TIMEOUT} 秒内 /confirm {token} 来确认')
try:
result = await asyncio.wait_for (future, timeout=CONFIRM_TIMEOUT)
except asyncio.TimeoutError:
await reply_msg (meta, f'超时,取消操作')
result = False
else:
await reply_msg (meta, f'成功确认')
finally:
del confirm_queue[token]
return result
def register_cmd (cmd):
def decorator (fn):
if cmd in commands:
raise Exception(f'试图第二次注册命令 {cmd}')
commands[cmd] = fn
def wrapper (*args, **kwargs):
return fn (*args, **kwargs)
return wrapper
return decorator
def trusted_sender (fn):
async def wrapper (*args, **kwargs):
meta = args[0]
if meta.uid in trusted_senders:
return await fn (*args, **kwargs)
return await reply_msg (args[0], f'执行该命令的权限不足')
return wrapper
@register_cmd ('/confirm')
async def cmd_confirm (meta, arg):
if len (arg) != 2:
return await reply_msg (meta, f'需要令牌')
token = arg[1]
if token not in confirm_queue:
return await reply_msg (meta, f'无效令牌')
uid = base64.b64decode (token).decode ('utf-8')[:-16]
if uid != str (meta.uid):
return await reply_msg (meta, f'错误的确认者。期望 {uid},得到 {meta.uid}')
confirm_queue[token].set_result (True)
@register_cmd ('/testre')
async def cmd_testre (meta, arg):
res = await wait_reply (meta, f'请回复这条消息')
if not res:
await reply_msg (meta, '为啥不回复?')
await reply_msg (meta, f'你说:{' '.join (res)}')
@register_cmd ('/ping')
async def cmd_ping (meta, arg):
s = f'PONG {meta.uid}'
if meta.uid in trusted_senders:
s += ' (privileged)'
if await db_banned (meta.uid):
s += ' (banned)'
await reply_msg (meta, s)
MAX_BINDS = 3
@register_cmd ('/bind')
async def cmd_bind (meta, arg):
if len (arg) != 2:
return await reply_msg (meta, f'需要 WyOJ 用户名\nUsage: /bind username')
name = arg[1]
if re.match (r'^([A-Za-z0-9_]*)$', name) is None:
return await reply_msg (meta, '不合法用户名')
if not await confirm (meta, f'确认将 {meta.uid} 绑定到 {name} 吗?'):
return
if await db_check_bound (name):
qq, _ = await db_query_by_name (name)
return await reply_msg (meta, f'无法绑定 {name};已绑定到 {qq}')
if await db_count_bound (meta.uid) >= MAX_BINDS:
return await reply_msg (meta, f'无法绑定更多账号。单个 QQ 绑定最大值为 {MAX_BINDS}')
await db_insert_bind (meta.uid, name)
wyoj_enable (meta.uid, name)
await reply_msg (meta, f'成功将 {name} 绑定到 {meta.uid}')
@register_cmd ('/rebind')
@trusted_sender
async def cmd_rebind (meta, arg):
if len (arg) != 2:
return await reply_msg (meta, f'需要 WyOJ 用户名\nUsage: /bind username')
name = arg[1]
if re.match (r'^([A-Za-z0-9_]*)$', name) is None:
return await reply_msg (meta, '不合法用户名')
if not await db_check_bound (name):
return await reply_msg (meta, f'无绑定')
qq, _ = await db_query_by_name (name)
await db_delete_bind (name)
await db_insert_bind (qq, name)
wyoj_enable (qq, name)
await reply_msg (meta, f'已重新绑定')
@register_cmd ('/refresh')
@trusted_sender
async def cmd_refresh (meta, arg):
q = await db_query_binds ()
s = ''
cnt = 0
for qq, name in q:
await db_delete_bind (name)
await db_insert_bind (qq, name)
wyoj_enable (qq, name)
s += f'{qq}\t\t{name}\n'
cnt += 1
await reply_msg (meta, f'已成功绑定:\n{s}\n计 {cnt} 人')
@register_cmd ('/unbind')
async def cmd_unbind (meta, arg):
if len (arg) != 2:
return await reply_msg (meta, f'需要 WyOJ 用户名\nUsage: /unbind username')
name = arg[1]
if re.match (r'^([A-Za-z0-9_]*)$', name) is None:
return await reply_msg (meta, '不合法用户名')
if not await db_check_bound (name):
return await reply_msg (meta, '该账号未绑定')
qq, _ = await db_query_by_name (name)
if qq != str (meta.uid):
if meta.uid in trusted_senders:
await reply_msg (meta, f'你是管理员 {meta.uid},强制解绑,等待确认')
else:
return await reply_msg (meta, f'{name} 与 {qq} 的绑定无法由你 ({meta.uid}) 解绑')
if not await confirm (meta, f'确认将 {meta.uid} 从 {name} 解绑吗?'):
return
if not await db_check_bound (name):
return await reply_msg (meta, f'尚无绑定,无法解绑')
await db_delete_bind (name)
wyoj_disable (name)
await reply_msg (meta, f'成功将 {meta.uid} 与 {name} 解绑')
@register_cmd ('/adminize')
@trusted_sender
async def cmd_adminize (meta, arg):
if len (arg) not in [ 2, 3 ]:
return await reply_msg (meta, f'需要用户名及时间\nUsage: /adminize username [time-in-minutes]')
name = arg[1]
if re.match (r'^([A-Za-z0-9_]*)$', name) is None:
return await reply_msg (meta, '不合法用户名')
time = -1
if len (arg) == 3:
try:
time = int (arg[2])
except ValueError:
return await reply_msg (meta, f'不合法的时间 {arg[2]}')
if not await confirm (meta, f'确定要赋予 {name} 以 {time} 分钟的管理员权限吗?'):
return
wyoj_adminize (name)
await reply_msg (meta, f'{name} 已被赋予管理员权限')
if time > 0:
await asyncio.sleep (time * 60)
wyoj_deadminize (name)
await reply_msg (meta, f'{name} 的管理员权限已到期')
@register_cmd ('/deadminize')
@trusted_sender
async def cmd_deadminize (meta, arg):
if len (arg) not in [ 2, 3 ]:
return await reply_msg (meta, f'需要用户名\nUsage: /deadminize username')
name = arg[1]
if re.match (r'^([A-Za-z0-9_]*)$', name) is None:
return await reply_msg (meta, '不合法用户名')
if not await confirm (meta, f'确定要取消 {name} 的管理员权限吗?'):
return
wyoj_deadminize (name)
await reply_msg (meta, f'{name} 已被赋予管理员权限')
async def cmd_query_qq (meta, arg):
qq = arg[2]
try:
int (qq)
except ValueError:
await reply_msg (meta, f'无效 QQ 号 {qq}')
res = await db_query_by_id (qq)
await reply_msg (meta, f'QQ {qq} 绑定到 {len (res)} 个账号:{", ".join (map (lambda x: x[1], res))}')
async def cmd_query_me (meta, arg):
arg.append ('qq')
arg.append (str (meta.uid))
await cmd_query_qq (meta, arg)
async def cmd_query_name (meta, arg):
name = arg[2]
if re.match (r'^([A-Za-z0-9_]*)$', name) is None:
return await reply_msg (meta, '不合法用户名')
res = await db_query_by_name (name)
if not res:
await reply_msg (meta, f'{name} 未绑定')
else:
await reply_msg (meta, f'{name} 绑定到 {res[0]}')
@trusted_sender
async def cmd_query_all (meta, arg):
await reply_msg (meta, f'绑定表:\n{"\n".join (map (lambda x: x[0] + "\t\t" + x[1], await db_query_binds ()))}')
@trusted_sender
async def cmd_query_banned (meta, arg):
await reply_msg (meta, wyoj_banned ())
@trusted_sender
async def cmd_query_admins (meta, arg):
await reply_msg (meta, wyoj_admins ())
@register_cmd ('/query')
async def cmd_query (meta, arg):
if len (arg) == 1:
return await cmd_query_me (meta, arg)
elif len (arg) == 2:
if arg[1] == 'all':
return await cmd_query_all (meta, arg)
elif arg[1] == 'banned':
return await cmd_query_banned (meta, arg)
elif arg[1] == 'admins':
return await cmd_query_admins (meta, arg)
elif len (arg) == 3:
if arg[1] == 'qq':
return await cmd_query_qq (meta, arg)
elif arg[1] == 'name':
return await cmd_query_name (meta, arg)
await reply_msg (meta, '期望零个或两个参数\nUsage: /query || /query qq qqid || /query name username')
@register_cmd ('/ban')
@trusted_sender
async def cmd_ban (meta, arg):
if len (arg) != 2:
return await reply_msg (meta, f'需要一个参数\nUsage: /ban username')
try:
qq = str (int (arg[1]))
except ValueError:
return await reply_msg (meta, f'无效 QQ 号 {qq}')
if not await confirm (meta, f'确定要封禁 {qq} 及其名下的所有账号吗?'):
return
await db_ban (qq)
res = await db_query_by_id (qq)
for _, name in res:
wyoj_disable (name)
await reply_msg (meta, f'被封禁的用户:{", ".join (map (lambda x: x[1], res))}')
@register_cmd ('/unban')
@trusted_sender
async def cmd_unban (meta, arg):
if len (arg) != 2:
return await reply_msg (meta, f'需要一个参数\nUsage: /unban username')
try:
qq = str (int (arg[1]))
except ValueError:
return await reply_msg (meta, f'无效 QQ 号 {qq}')
if not await confirm (meta, f'确定要解封 {qq} 吗(不解封账号)?'):
return
await db_unban (qq)
await reply_msg (meta, '成功解封')
@register_cmd ('/banlist')
async def cmd_banlist (meta, arg):
await reply_msg (meta, f'被封禁的 QQ:{", ".join (map (lambda x: x[0], await db_banned_all ()))}')
@register_cmd ('/entrust')
@trusted_sender
async def cmd_entrust (meta, arg):
global trusted_senders
if len (meta.ats) == 0:
await reply_msg (meta, f'需要 At 某人\nUsage: [@someone..] /entrust [@someone..]')
if not await confirm (meta, f'确定信任 {' '.join (meta.ats)} 吗?'):
return
for i in meta.ats:
try:
int (i)
except ValueError:
return await reply_msg (meta, f'非法 At')
trusted_senders += map (int, meta.ats)
await reply_msg (meta, f'成功信任')
@register_cmd ('/detrust')
@trusted_sender
async def cmd_detrust (meta, arg):
global trusted_senders
if len (meta.ats) == 0:
await reply_msg (meta, f'需要 At 某人\nUsage: [@someone..] /entrust [@someone..]')
if not await confirm (meta, f'确定取消信任 {' '.join (meta.ats)} 吗?'):
return
for i in meta.ats:
try:
int (i)
except ValueError:
return await reply_msg (meta, f'非法 At')
if int (i) not in trusted_senders:
await reply_msg (meta, '其实 {i} 并未被信任。')
for i in meta.ats:
trusted_senders.remove (int (i))
await reply_msg (meta, f'成功取消信任')
@register_cmd ('/trusts')
async def cmd_trusts (meta, arg):
await reply_msg (meta, f'信任用户:{' '.join (map (str, trusted_senders))}')
async def run_cmd (cmd):
proc = await asyncio.create_subprocess_shell (
cmd,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE)
stdout, stderr = await proc.communicate ()
return stdout.decode ('utf-8'), stderr.decode ('utf-8')
@register_cmd ('/upload')
@trusted_sender
async def cmd_upload (meta, arg):
pid = arg[1]
try:
pid = int (pid)
except ValueError:
return await reply_msg (meta, f'非法题号')
if len (meta.refs) != 1:
return await reply_msg (meta, f'需要有且仅有一个指向题目数据压缩包的引用')
if not os.path.exists (download_dir (meta.refs[0])):
return await reply_msg (meta, f'数据文件未被下载:错误的引用或者已经超时')
await reply_msg (meta, f'正在上传数据')
stdout, stderr = await run_cmd (f'/home/ryp/upload {pid} {download_dir (meta.refs[0])}')
await reply_msg (meta, f'命令执行完毕。标准输出:\n{stdout}\n\n标准错误:{stderr}\n' \
f'若无错误,请打开 https://oj.ryp.org.cn/problem/{pid}/manage/data 点击校验配置并同步数据')
async def dispatch (meta):
if not meta.cmd[0] in commands:
return await reply_msg (meta, f'未知命令 {meta.cmd[0]}')
await commands[meta.cmd[0]] (meta, meta.cmd)
async def handle_msg (data):
try:
data = json.loads (data)
meta = MessageMeta (data)
if meta.gid != GROUP_ID:
return
if data['message'][0]['type'] == 'file':
return await receive_file (meta, data)
if meta.msg[0] != '/':
return
print (f'收到群 {meta.gid} 的用户 {meta.uid} 的命令:{' '.join (meta.cmd)}')
await dispatch (meta)
except KeyError as e:
pass
except Exception as e:
print (f'未知错误:{e}')
traceback.print_exc ()
async def client_loop ():
global ws, sqlconn
ws = await websockets.connect (wsserver)
sqlconn = await aiosqlite.connect ('data.db')
print ('已成功连接到 NapCat 服务器')
async for msg in ws:
asyncio.create_task (handle_msg (msg))
if __name__ == '__main__':
asyncio.run (client_loop ())import tkinter as tk
import tkinter.simpledialog
from tkinterdnd2 import DND_FILES, TkinterDnD
rt = TkinterDnD.Tk ()
rt.title ('WyOJ 数据配置工具')
def ask_subtask_nr ():
n = tk.simpledialog.askinteger (title='Subtask 数量',
prompt='要配置的 Subtask 数量',
initialvalue=0)
print (f'你想配置 {n} 个 Subtask')
return n
def configure_subtask (i):
def config ():
win = tk.Toplevel (rt)
win.title (f'配置 Subtask {i}')
droparea = tk.Label (win,
text='>>> 请将本 Subtask 中的测试点拖到这里 <<<',
height=10)
txt = tk.Text (win)
txt.pack ()
def drop (ev):
fp = ev.data
txt.insert (tk.END, f'{fp}\n')
droparea.drop_target_register (DND_FILES)
droparea.dnd_bind ('<<Drop>>', drop)
droparea.pack ()
txt.pack ()
return config
buttons = list ()
def create_subtask_buttons (nr):
for i in range (1, nr + 1):
butt = tk.Button (rt, text=f'配置 Subtask {i}',
command=configure_subtask (i))
butt.place (x=80, y=20 + i * 40, width=60, height=30)
butt.pack ()
buttons.append (butt)
nr = ask_subtask_nr ()
create_subtask_buttons (nr)
rt.mainloop ()为了减少完全以刷号为意义的小号出现,并且将线上可能出现的不恰当行为言论与线下相关联,我们决定 任何账号都必须绑定到 QQ 以进行活动。
具体方法:
加入 QQ 群 1061173220,口令是 wyojyydsrypnb
在群中发消息 /bind XXX,其中 XXX 是你的用户名
WyOJ Musume,也就是 WyOJ 的机器人,会回应你的消息。
根据 WyOJ Musume 的指示来完成操作,绑定成功后,你的账号便可用。
注意:
每个账号只能绑定一个 QQ,但一个 QQ 可以绑定最多三个账号。
若某个账号决定被封禁,其对应的 QQ 会被封禁,对应 QQ 下的所有账号也会被封禁。
WyOJ Musume 有时候可能会因为登录时间太长而掉线,这时候不要着急,管理员看到后会修复,并在此之后让你重试。
递推,比正解还麻烦,略。
超级笨蛋博弈论,找规律。
考虑倒推,剩 $1$ 到 $m$ 张是先手有必胜策略,$m+1$ 是后手有必胜策略。
继续,考虑 $m+2$ 到 $2m+1$,先手方可以将纸牌数控制为 $m+1$,使得对方从 $m+1$ 开始取,进而自己有必胜策略;若 $2m+2$,则不论如何取,剩下纸牌在 $[m+2,2m+1]$ 范围内,后手有必胜策略。
归纳可知,若初始纸牌数 $n$ 为 $m+1$ 的倍数,后手有必胜策略,否则先手有必胜策略。
$n\le 10$,乱搞点暴搜之类的东西大概就可以过的吧(其实我也不知道有什么具体的办法)。
$n\le 10^3$,是不加优化的 DP 做法。
问题的一个难解决的地方就在于分组的实质是选数并建立集合,而不是选取某一段。但要使每个集合中的最大值减最小值(集合即每一组,值即体积,下同)尽可能小,每个集合的元素就一定是排序后的数中某连续的一段,于是直接按物品体积进行排序,这样就可以把集合问题转化为分段问题了。
设 $f_i$ 表示将前 $i$ 个物品进行分组的最小“不整齐程度”,起初 $f_0=0$,有如下转移:
$$f_i=\begin{cases}v_i-v_1 & 1\le i< 2k \\\min \limits_{j=0}^{i-k}(f_j+v_i-v_{j+1}) & 2k\le i\le n \end{cases}$$
对于 $2k\le i\le n$ 的情况,枚举每个 $j$,取最小的 $f_j-v_{j+1}$ 进行转移,$f_n$ 即为最终答案。
转移次数 $O(n)$,转移复杂度 $O(n)$,总的时间复杂度为 $O(n^2)$。
考虑对上述 $O(n^2)$ 的做法进行优化。
复杂度高的原因出在每次取 $\min \limits_{j=0}^{i-k}(f_j-v_{j+1})$ 时需要 $O(n)$ 枚举 $j$,而实际上 $\left [0,i-k \right ]$ 是一个左端静止且右边递增的区间,因此可以直接用一个变量维护这个最值(甚至不需要写单调队列)。
现在,转移次数 $O(n)$,转移复杂度 $O(1)$,DP 的时间复杂度为 $O(n)$,由于排序是 $O(n \log n)$ 的,故总的时间复杂度为 $O(n \log n)$,可以通过此题。
#include<iostream>
#include<cstdio>
#include<algorithm>
#define ll long long
using namespace std;
const int N=1e6+5;
const ll inf=1e18;
int n,k;
ll v[N],f[N],mini;
int main()
{
scanf("%d%d",&n,&k);
for(int i=1;i<=n;i++)
{
scanf("%d",&v[i]);
}
sort(v+1,v+1+n);
for(int i=1;i<=n;i++)
{
if(i<k*2)f[i]=v[i]-v[1];
else
{
mini=min(mini,f[i-k]-v[i-k+1]);
f[i]=v[i]+mini;
}
}
printf("%lld",f[n]);
return 0;
}$O(n^2)$ 求出任意两点之间的边权(即时间,下同),直接从 $1$ 跑最短路。
考虑边权与坐标的关系,若从一点 $i$ 走到 $j$ 的时间是 $|x_i-x_j|$,且存在另一点 $k$ 满足 $x_k$ 在 $x_i,x_j$ 之间,那么边 $(i,j)$ 可被边 $(i,k),(k,j)$ 代替,也即经过 $k$ 不会使时间更长,这是因为:
$$\begin{aligned} dis_{i,j} &= |x_i-x_j| \\ &= |x_i-x_k| + |x_k-x_j| \\ &\ge \min \left\{ |x_i-x_k|,|y_i-y_k| \right\} + \min \left\{ |x_k-x_j|,|y_k-y_j| \right\} \\ &= dis_{i,k} +dis_{k,j} \end{aligned}$$
纵坐标同理。
对此推广,我们得到结论:对所有点按横坐标排序,相邻点连边,然后纵坐标做相同处理,然后跑最短路即可。边数是 $O(n)$ 的,可以通过此题。
#include<iostream>
#include<cstdio>
#include<vector>
#include<queue>
#include<algorithm>
#define ll long long
using namespace std;
const int N=1e5+5;
const ll inf=1e18;
int n;
struct node
{
int num;
ll x,y;
}dot[N];
bool cmp1(node a,node b)
{
return a.x<b.x;
}
bool cmp2(node a,node b)
{
return a.y<b.y;
}
struct edge
{
int v;
ll w;
};
vector<edge>e[N];
priority_queue<pair<ll,int> >q;
ll d[N];
bool vis[N];
void dijkstra()
{
for(int i=1;i<=n;i++)d[i]=inf;
d[1]=0;
q.push(make_pair(0,1));
while(!q.empty())
{
int u0=q.top().second;
q.pop();
if(vis[u0])continue;
vis[u0]=1;
for(int i=0;i<e[u0].size();i++)
{
int v0=e[u0][i].v,w0=e[u0][i].w;
if(d[u0]+w0<d[v0])
{
d[v0]=d[u0]+w0;
q.push(make_pair(-d[v0],v0));
}
}
}
}
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
dot[i].num=i;
scanf("%lld%lld",&dot[i].x,&dot[i].y);
}
sort(dot+1,dot+1+n,cmp1);
for(int i=1;i<n;i++)
{
int u0=dot[i].num,v0=dot[i+1].num,
w0=dot[i+1].x-dot[i].x;
e[u0].push_back({v0,w0});
e[v0].push_back({u0,w0});
}
sort(dot+1,dot+1+n,cmp2);
for(int i=1;i<n;i++)
{
int u0=dot[i].num,v0=dot[i+1].num,
w0=dot[i+1].y-dot[i].y;
e[u0].push_back({v0,w0});
e[v0].push_back({u0,w0});
}
dijkstra();
printf("%lld",d[n]);
return 0;
}$O(n^3)$ 超级大暴力,略。
容易知道均衡区间不存在,答案全是 $0$。
建 $ST$ 表维护区间 $min$ 和 $\max$,$O(1)$ 判断一个区间是否合法,时间复杂度 $O(n^2)$。
这一档区分出常数太大的 $\log$ 以及一些神秘复杂度,像根号、$\log^2$ 之类的,放到下面讲。
我们考虑位置 $i$ 成为一个均衡区间的左端点需要满足的限制(右端点同理):
也就是说,$i$ 符合条件需要右端点 $j$ 足够大。
我们做四次单调栈分别预处理出每个 $v_i$ 的左侧和右侧第一个大于或小于 $v_i$ 的数的位置(不存在则用 $0$ 或 $n+1$ 补充)。左侧的两个位置取 $\min$,记为 $L_i$;右侧取 $\max$,记为 $R_i$。
那么 $[i,j]$ 是均衡区间的充要条件是,$j>R_i$ 且 $L_j>i$。
因此,将所有 $(j,L_j)$ 视为平面上的点,$i$ 的答案即平面上符合上述条件的点的个数,离线下来用树状数组做二位数点即可。注意要离散化。
这个做法有 $O(n\log n)$ 的时间复杂度和 $O(n)$ 的空间复杂度。
import os
import hashlib
def hash (path, method=hashlib.md5):
h = method ()
with open (path, 'rb') as f:
while b := f.read (8192):
h.update (b)
return h.hexdigest ()
q = dict ()
for root, _, k in os.walk ('.'):
for d in k:
i = root + '/' + d
print (i)
h = hash (i)
print (h)
if h in q:
print (f'{i} (Cached from {q[h]})')
os.system (f'ln -sf {q[h]} {i}')
else:
print (f'{i} (Uncached)')
q[h] = iT4 的数据有误,已经修好。
经过我一晚的奋战,WyOJ 已经成功加入了一个 UB 检测器!

具体使用,只需要把语言选为 C++17ubsan,然后重新提交!非常简单也非常好用!!!!!!
然后,点击 Runtime Error 的数据点,可以看到 output 区域包含了具体 UB 信息。
具体的实现是,我把 C++17ubsan 语言的 stderr 输出到了输出文件,于是 output 就会包含原先 stderr 的内容。
如果你的 stderr 内容过多,可能导致 UB 信息被挤掉看不到。 这时可以 #define stderr stdout,然后重新提交。
原先 AC 的点会变成 WA
使用检测器后的代码常数会变大不少,所以可能导致 TLE。
比赛期间看不到 output,所以本功能也自然在赛时无用。
同时,Special Judge 和 Hack 功能也已经修好!
整理了一些关于 Splay 的资料,一个简洁美丽而高效的数据结构。
Splay 是最简洁的平衡树之一,支持维护区间信息。相比线段树,其可以动态地删点、加点,更加灵活;相比分块,其复杂度是均摊对数,更加高效。
在形态变化时,Splay 并不通过维护一系列性质来保证树高,而是通过伸展保证均摊复杂度。这让它少了常见平衡树的繁杂分讨,但常数也要大不少。
Splay 首先是一棵二叉搜索树,由许多节点组成。我们在每个节点维护父亲的左右儿子指针,以及键值。如有需要,还可以维护它子树内的信息,如它的子树大小。维护子树大小,可以实现快速查询第 k 大或者某数排名。
Splay 的核心操作是伸展(splay)。伸展某个节点 $x$,意味着将 $x$ 节点提升到根,同时更新所维护的子树信息。原来的根在伸展后成为某个普通内部节点。伸展操作的均摊复杂度是对数。
如果能够实现伸展操作,就可以方便地进行许多操作:
插入。插入与普通二叉树的插入相同,按照二叉树的遍历方法找到某个叶子节点,将新值插入到该叶子的儿子下。不同的是,在插入某个点后,为了保证复杂度正确,我们要将这个节点伸展到根。
删除。首先将这个节点伸展到根,然后将其与其儿子断开。这时原树分裂成两个子树,考虑合并它们。找到左子树的最大值,由二叉树的性质,这个数一定小于右子树的最小值。因此,我们将 $y$ 伸展到根。这时 $y$ 的右儿子一定空,于是将右子树拼到其右儿子上即可。
查找某个数。按照二叉树的查找方法,一直找到这个数,或者某个叶子。将最后找到的节点伸展到根。
查询排名。首先查找这个数,伸展到根。然后小于其的数数量就是现在根左子树的大小。如果待查询的值不存在,还要考虑根是否小于这个数。
查询第 $k$ 大。和二叉树相同。从根节点开始遍历。如果当前节点 $x$ 左子树的大小,也就是小于 $x$ 的数字数量,大于等于 $k$,要找的节点在左子树;如果等于 $k - 1$,那么就是当前节点 $x$;否则,在右子树,并且 $k$ 减去左子树加上当前点大小。
查询前驱。伸展到根,然后找左子树的最大值,也就是一直向右走。如果查询的值不存在,特判根是否小于待查值。
查询后继。与查询前驱同。
查询区间。设待查询区间为 $[l, r]$,我们将 $l - 1$ 旋到根,$r + 1$ 旋到根的右儿子,那么根的右儿子的左儿子,其上的信息就是 $[l, r]$ 的信息。
现在,我们只需要有效地实现伸展操作,就可完成所需的一切操作。
考虑怎么将某个节点高度提升一。我们称这个操作为旋转。
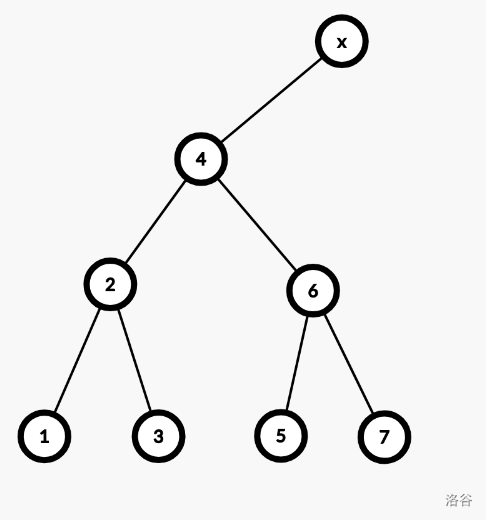
考虑怎么将 $2$ 提升到 $4$ 的位置。
那样,$4$ 该放到哪里?可以接到 $2$ 的右儿子上。$2$ 的右儿子放到哪里?放到 $4$ 的左儿子上,因为 $4$ 原来的左儿子是 $2$,现在已经空。其他子树不变。因此,变的只有 $2$ 和 $4$。
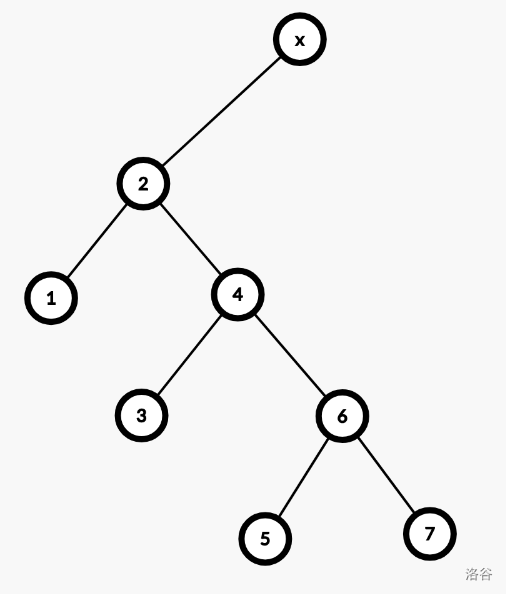
伸展操作能不能直接一直向上旋转呢?可以,但复杂度错误。
为了改善复杂度,我们需要引入双旋。
双旋是指,在伸展过程中,如果出现 $x$ 与 $x$ 的父亲同向,不能简单地旋转两次 $x$,而是要先旋转其父亲,再旋转 $x$。
我们如果想要将 $6$ 伸展到根,是不是需要双旋?答案是肯定的,因为 $4$ 和 $6$ 都是其父亲的右儿子,属于同向。如果是伸展 $3$,就不需要了。按照双旋的过程,我们先旋转 $4$,再旋转 $6$。也就是,先变成:
后旋转 $6$
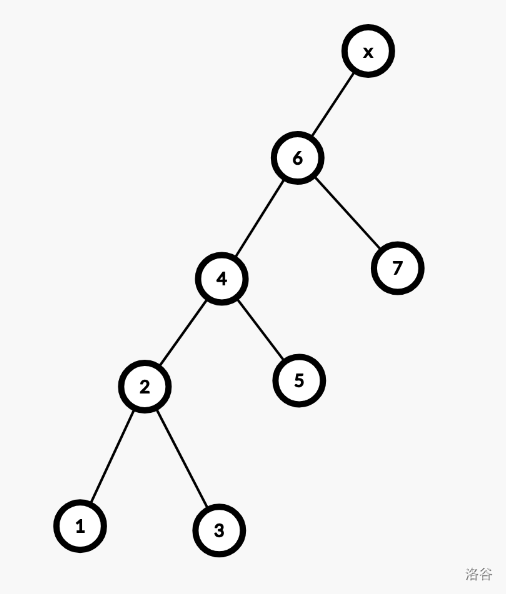
光看上图,可能感觉双旋和单旋没有什么区别,但实际上在复杂度分析时,使用双旋可以保证某个性质,进而保证复杂度正确。
总之,我们已经知道了怎样以正确的复杂度将 $x$ 伸展到根。有关 Splay 的基本操作,就介绍完毕了。
我们发现,Splay 的复杂度来源于两部分,一部分是遍历,另一部分是伸展。让最终遍历到节点马上被伸展到根,就可以把复杂度都算在伸展里,进而只需证明伸展的复杂度。
我们采用势能分析。势能分析是指,引入某个势能函数 $\Phi(D)$,描述某时数据结构的状态。
设每次操作的代价是 $c_i$,每次操作后数据结构为 $D_i$。要证 $\sum c_i$ 有某上界。如果 $\Phi(D_n) - \Phi(D_0) = O(F(n))$,$\Phi(D_n) - \Phi (D_0) + \sum c_i = \sum (c_i + \phi(D_i) - \phi(D_{i - 1})) = O(G(n))$,显然 $\sum c_i = O(F(n) + G(n))$。
这样有什么好处?我们考虑,Splay 等数据结构复杂度分析的难处,在于我们只知道 $c_i$ 的一个很松的上界,而不好直接分析 $\sum c_i$。实际上,某个大的 $c_i$ 对数据结构的影响也是大的,会导致后续的操作 $c_i$ 更小;换句话说,不会出现所有 $c_i$ 都取到上界的情况。
引入势能函数后,每个很大的 $c_i$,可以用一个很小的 $\Phi(D_i) - \Phi(D_{i-1})$ 来平衡。因而可以更方便地放缩,并得到上界。
我们设某个节点的势能函数为 $\phi(x) = \log \lvert x\rvert$($\log$ 均以二为底;$\lvert x\rvert$ 表示 $x$ 的子树大小),$\Phi(D) = \sum \phi(x)$。显然的,$0\le \Phi(D) \lt n\log n$,并且 $\Phi(D_n) - \Phi(D_0) = O(n\log n)$。我们要证明每次伸展操作的均摊复杂度是对数。
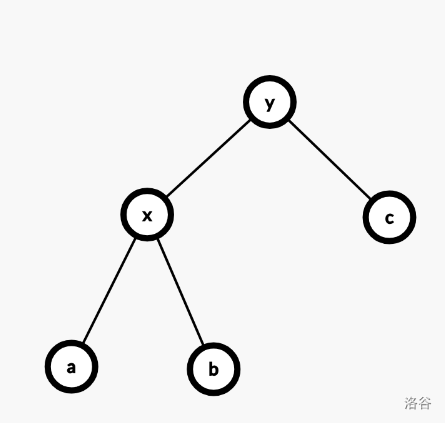
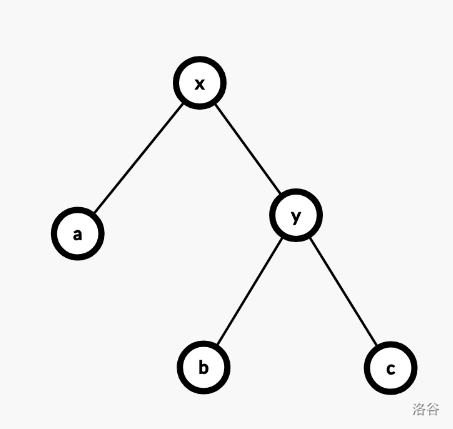
根据上面对 Splay 的介绍,我们可以将伸展分为三种具体操作。设 $x$ 为待伸展的节点,$y$ 为 $x$ 的父亲,$z$ 为 $y$ 的父亲。
zig,即一次单旋,在 $y$ 为根时候发生。直接旋转 $x$,其深度减少一。发现这种旋转最多发生一次。
zig-zig,即一次双旋,在 $y$ 和 $x$ 同向时发生。先旋转 $y$,后旋转 $x$。$x$ 深度减少二。
zig-zag,即两次对 $x$ 的单选,在 $x$ 和 $y$ 不同向时发生。$x$ 深度减少二。
伸展的过程是数次 zig-zig 与 zig-zag 的组合,加上可能存在的一次 zig。
旋转的复杂度为 $O(1)$,势能的变化量为
$\phi(x') + \phi(y') - \phi(x) - \phi(y) = \phi(y') - \phi(x) \le \phi(x') - \phi(x)$
因此摊还代价是 $O(1) + \phi (x') - \phi (x)$。
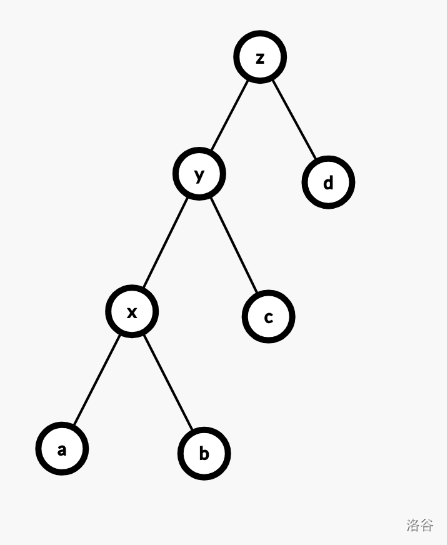
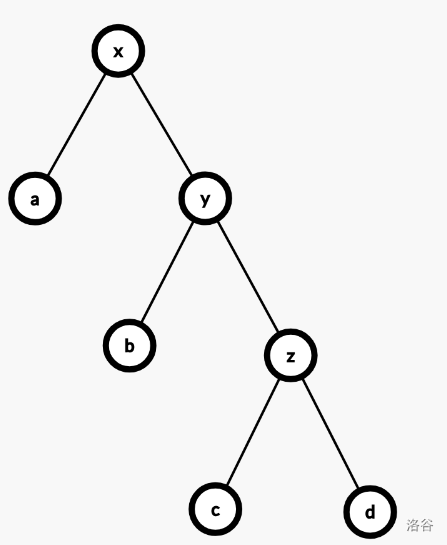
摊还代价是
$$ \begin{aligned} & c \\ =& 1 + \phi(x') + \phi(y') + \phi(z') - \phi(x) - \phi(y) - \phi(z) \\ =& 1 + \phi(y') + \phi(z') - \phi(x) - \phi(y) \\ \end{aligned} $$
考虑怎么把 $1$ 去掉,因为如果引入 $1$,就会导致最终复杂度与旋转次数有关。
有:
$$ \begin{aligned} 2\phi(x') - \phi(x) - \phi(z') = \log (\dfrac{\lvert x'\rvert^2}{\lvert x\rvert\lvert z'\rvert}) \ge 1 \end{aligned} $$
这是因为 $\lvert x'\rvert \ge \lvert x\rvert+\lvert z'\rvert$。注意到不双旋时,此不等式不满足。这也是为什么双旋才能保证复杂度。
用这个不等式代换常数 $1$,得到
$$ \begin{aligned} & c \\ \le& 2\phi(x') - \phi(x) - \phi(z') + \phi(y') + \phi(z') - \phi(x) - \phi(y) \\ \le& 2\phi(x') - 2\phi(x) + \phi(y') - \phi(y) \\ \le& 3\phi(x') - 3\phi(x) \\ =& O(\phi(x') - \phi(x)) \end{aligned} $$
成功将常数消去,同时和前面的 $\phi(x') - \phi(x)$ 保持了一致。
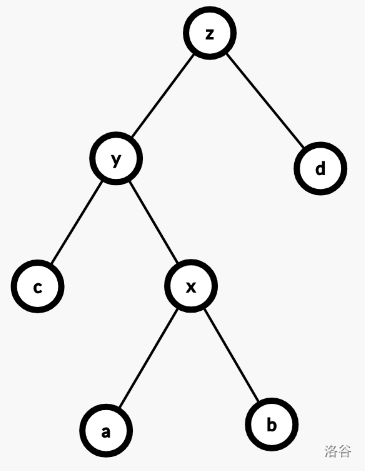
类似的,我们有不等式:$2\phi(x') - \phi(y') - \phi(z') = \log (\dfrac{\lvert x'\rvert^2}{\lvert y'\rvert\lvert z'\rvert})\ge 1$
$$ \begin{aligned} & c \\ &= 1 + \phi(x') + \phi(y') + \phi(z') - \phi(x) - \phi(y) - \phi(z) \\ &= 1 + \phi(y') + \phi(z') - \phi(x) - \phi(y) \\ &\le 2\phi(x') - \phi(y') - \phi(z') + \phi(y') + \phi(z') - \phi(x) - \phi(y) \\ &\le 2\phi(x') - 2\phi(x) - \phi(y) \\ &\le 2\phi(x') - 2\phi(x) \\ &= O(\phi(x') - \phi(x)) \end{aligned} $$
分析得到,zig 的摊还代价为 $O(1 + \phi(x') - \phi(x))$,而这种旋转最多一次;其他的两种旋转,摊还代价都是 $O(\phi(x') - \phi(x))$。这样,伸展的总代价就是 $O(\log \lvert x'\rvert - \log \lvert x\rvert + 1) = O(\log n)$。我们成功证明了伸展的复杂度是摊还对数,由此知道 Splay 的复杂度是正确的。
跳表实际上是一个多层链表,每一层链表都有序。从下到上(层数从小到大),链表逐渐变小。一个元素位于第 $k$ 层的概率是 $p^k$,实践中一般会限制层数。
因此 $n$ 个元素的跳表的第 $k$ 层链表的大小期望是 $np^k$,呈指数级下降。这保证复杂度正确。
对于实践,我们对每一个节点,维护它的值以及它在每一层的链表指针 nxt[]。
接下来考虑操作。
最基本的操作是在跳表中查找一个节点。由于每一层链表有序,并且越高层节点越少,我们可以从最高层开始遍历。由于在高层的节点一定也在低层,并且每一层链表都具有单调性,所以这个算法正确。
考虑复杂度。显然的,如果证明了搜索的复杂度正确,跳表的其他一系列操作复杂度都正确。
注意到,搜索某个节点,实际上就是从 rank $1$ 走到 rank $k$ 的过程。与朴素链表不同的是,跳表允许不连续地从 $1$ 走到 $k$,这就是它节省的复杂度。
有一个比较简单的感性证明。考虑在第 $k$ 层,rank $i$ 走到 $rank j$ 的期望代价是 $(j - i) p^k$(二项分布),这个代价随着层数增加而减小。
严格证明可以看 OI Wiki,但是我觉得我这个感性就比较够了。
然后考虑更多的操作。考虑插入一个节点。我们需要决定把这个节点到前多少层,这可以随出来。我们找到这些层上这个节点的前驱,就可以按照链表的方法,把它插入到跳表中。删除一个节点同样简单,前驱后继也很基本。
第 $k$ 大和查排名不出所料地需要维护信息。
维护啥?如果能维护出每个节点的 $rank$,那就跟玩一样了。虽然我们显然办不到,但是我们可以维护每一层上相邻两个节点之间的实际距离,也就是排名差。
这个玩意儿是很好维护的。插入的时候我们将后继的排名差加一,删除的时候减一即可。于是我们做完了。
好吧,这个东西好像不那么好维护,但是我现在不太感兴趣了。我打算用 Rust 写一个类似 Redis 的内存数据库,主要是为了练习 Rust。