本文章由 WyOJ Shojo 从洛谷专栏拉取,原发布时间为 2022-11-02 10:59:09
A. 假期计划
题意:有一个无向图,点有点权。定义两个节点“可达”当且仅当这两个节点的最短路不超过 $k+1$。求一组互不相同的节点 $\{a,b,c,d\}$ 使得 $1\leftrightarrow a\leftrightarrow b\leftrightarrow c\leftrightarrow d\leftrightarrow 1$ 每步均可达且这四个点的点权和尽可能大。$n\le 2500$。
首先跑 $n$ 遍 BFS,预处理出每两个点的距离。然后我们可以考虑枚举中间两个节点 $b,c$,处理边上两个节点 $a,d$。首先中间两个节点必须是可达的,否则跳过;然后需要满足 $1\leftrightarrow a\leftrightarrow b$,$c\leftrightarrow d\leftrightarrow 1$。由于“可达”是双向的,我们可以对每个节点 $x$ 预处理出所有满足 $1\leftrightarrow y\leftrightarrow x$ 的节点 $y$ 的集合并按 $y$ 的点权从大到小排序。于是容易想到,当我们枚举了 $b,c$ 时,只需要独立地考虑最大的 $v[a]$ 满足 $1\leftrightarrow a\leftrightarrow b$ 和最大的 $v[d]$ 满足 $1\leftrightarrow d\leftrightarrow c$ 即可。但事实并非如此。有可能对于最大的 $v[a]$,$a=c$,或对于最大的 $v[a],v[d]$,$a=d$,这些都会产生冲突(因为要求互不相同),于是可能需要跳过一些节点。容易证明对于 $b,c$ 只需要考虑前三大的即可,所以乘一个 $9$ 的常数暴力判断。
#include<bits\/stdc++.h>
using namespace std;
#define int long long
int v[2510];
vector<int> a[2510];
bool e[2510][2510];
vector<int> to[2510];
bool vis[2510];
signed main() {
int n,m,kk;
scanf("%lld%lld%lld",&n,&m,&kk);
for(int i=2;i<=n;i++)
scanf("%lld",&v[i]);
for(int i=1;i<=m;i++) {
int x,y;
scanf("%lld%lld",&x,&y);
a[x].push_back(y);
a[y].push_back(x);
}
for(int i=1;i<=n;i++) {
memset(vis,0,sizeof(vis));
queue<pair<int,int> > q;
q.push({i,0});
while(!q.empty()) {
auto u=q.front();q.pop();
if(u.second>kk+1) break;
if(vis[u.first]) continue;
vis[u.first]=1,e[i][u.first]=1;
for(int v:a[u.first])
if(!vis[v]) q.push({v,u.second+1});
}
}
for(int i=2;i<=n;i++) {
for(int j=2;j<=n;j++)
if(i!=j&&e[i][j]&&e[1][j])
to[i].push_back(j);
sort(to[i].begin(),to[i].end(),[&](int x,int y) {
return v[x]>v[y];
});
}
int ans=0;
for(int i=2;i<=n;i++)
for(int j=i+1;j<=n;j++) {
if(!e[i][j]) continue;
for(int k=0;k<min(3ll,(int)to[i].size());k++)
for(int l=0;l<min(3ll,(int)to[j].size());l++)
if(to[i][k]!=j&&to[j][l]!=i&&to[i][k]!=to[j][l])
ans=max(ans,v[i]+v[j]+v[to[i][k]]+v[to[j][l]]);
}
printf("%lld\n",ans);
return 0;
}
B. 策略游戏
题意:给你两个数组 $a(n),b(m)$,每次询问 $l_1,r_1,l_2,r_2$,进行如下博弈:第一个人先选一个 $i\in[l_1,r_1]$,第二个人再选一个 $j\in[l_2,r_2]$,其中第一个人想使 $a_i\cdot b_j$ 最大,第二个人相反。求最终结果。$n,m,q\le 10^5$。
容易发现,此题可以直接分类讨论正负后贪心。如果第一个人选正数,那么第二个人一定会选能选的最小的数。如果第二个人能选到负数则一定会选,此时第一个人选的正数越小越好,否则越大越好。如果第一个人选负数,那么第二个人一定会选最大值。如果第二个人能选到正数则一定会选,此时第一个人选的越大(即越接近 $0$)越好,否则越小越好。
实现上,可以使用线段树维护两个序列的正数最大值、最小值和负数最大值、最小值,每次区间询问合并区间信息即可。
#include<bits\/stdc++.h>
using namespace std;
int a[2][100010];
#define mid (t[now].l+t[now].r)\/2
#define lson now*2
#define rson now*2+1
struct node {
int l,r,maxp,minp,maxn,minn;
bool havep,haven;
node():havep(0),haven(0){}
};
struct segtree {
node t[400010];
node merge(node x,node y) {
node res;
res.l=x.l,res.r=y.r;
res.havep=(x.havep||y.havep);
res.haven=(x.haven||y.haven);
if(x.havep&&y.havep) {
res.maxp=max(x.maxp,y.maxp);
res.minp=min(x.minp,y.minp);
}
else if(x.havep||y.havep) {
res.maxp=x.maxp*x.havep+y.maxp*y.havep;
res.minp=x.minp*x.havep+y.minp*y.havep;
}
if(x.haven&&y.haven) {
res.maxn=max(x.maxn,y.maxn);
res.minn=min(x.minn,y.minn);
}
else if(x.haven||y.haven) {
res.maxn=x.maxn*x.haven+y.maxn*y.haven;
res.minn=x.minn*x.haven+y.minn*y.haven;
}
return res;
}
void build(int now,int l,int r,bool flag) {
t[now].l=l,t[now].r=r;
if(l==r) {
if(a[flag][l]>=0) {
t[now].havep=1;
t[now].maxp=t[now].minp=a[flag][l];
}
else {
t[now].haven=1;
t[now].maxn=t[now].minn=a[flag][l];
}
return;
}
build(lson,l,mid,flag);
build(rson,mid+1,r,flag);
t[now]=merge(t[lson],t[rson]);
}
node query(int now,int l,int r) {
if(l<=t[now].l&&r>=t[now].r) return t[now];
node res;
if(l<=mid) res=merge(res,query(lson,l,r));
if(r>mid) res=merge(res,query(rson,l,r));
return res;
}
} T1,T2;
void chkmax(long long &x,long long y) {x=(x>y)?x:y;}
int main() {
int n,m,q;
scanf("%d%d%d",&n,&m,&q);
for(int i=1;i<=n;i++)
scanf("%d",&a[0][i]);
for(int i=1;i<=m;i++)
scanf("%d",&a[1][i]);
T1.build(1,1,n,0);
T2.build(1,1,m,1);
while(q--) {
int l1,r1,l2,r2;
scanf("%d%d%d%d",&l1,&r1,&l2,&r2);
node A=T1.query(1,l1,r1);
node B=T2.query(1,l2,r2);
long long ans=-1e18;
if(A.havep) {
if(B.haven) chkmax(ans,1ll*A.minp*B.minn);
else chkmax(ans,1ll*A.maxp*B.minp);
}
if(A.haven) {
if(B.havep) chkmax(ans,1ll*A.maxn*B.maxp);
else chkmax(ans,1ll*A.minn*B.maxn);
}
printf("%lld\n",ans);
}
return 0;
}
C. 星战
题意:有一张简单的有向图(不保证连通),每条边有可用和不可用两种状态,初始每条边都可用。定义一个图是合法的,当且仅当:
- 从每个点开始都存在一个合适的移动方式使得能够无限移动下去。
- 每个点有且仅有一条出边。
你需要进行 $q$ 次操作,每次如下:
- 给出 $u,v$,将 $u\to v$ 变为不可用。保证此前处于可用状态。
- 给出 $u$,将所有 $x\to u$ 全部变为不可用。
- 给出 $u,v$,将 $u\to v$ 变为可用。保证此前处于不可用状态。
- 给出 $u$,将所有 $x\to u$ 全部变为可用。
每次操作后回答这张图是否合法。$n,m,q\le 5\times 10^5$。
可以发现,合法的限制一是没有用的。因为如果满足了限制二,该有向图一定为一个基环内向树森林,于是每个节点必然可以通向一个环。可以通过反证法简单地证明:如果存在某个点不能无限移动下去,设它的终点为 $x$,根据限制二,$x$ 必然有出边,故不能成为终点,与假设矛盾。
于是问题转化为每次操作后判断是否每个点的出度均为 $1$。
我们考虑通过哈希来维护这一过程。我们给每个点赋一个随机权值,维护当前每条边起点的权值和 $nowsum$ 并预处理所有点的权值和 $all$。此时如果 $nowsum=all$ 等于每个点的权值和,我们就可以认为每个点恰有一个出边。
对于暴力连边和断边的操作,可以直接在 $nowsum$ 上加减。但是对于断点和恢复点的操作我们没法维护。所以考虑增加维护的状态。定义 $now_i$ 为当前可用的、以 $i$ 为终点的所有起点权值和;$sum_i$ 为所有(包括不可用)以 $i$ 为终点的起点权值和。于是,最终方案如下:
- 暴力连断边:根据定义,$nowsum$ 增/减 $x$ 的权值,$now_y$ 同样增/减 $x$ 的权值。
- 删点、恢复点:使用 $now_x$ 和 $sum_x$ 计算出 $nowsum$ 需要改变的值,更新即可。
可以感性理解成势能和动能的转化:$now_i$ 维护每个终点的势能(即其起点的权值和),势能越大,删掉该点时 $nowsum$ 就会减少更多。连边和断边相当于直接更改其终点的势能,而连点和断点相当于将其势能归零/回满。
#include<bits\/stdc++.h>
using namespace std;
long long a[500010],sum[500010],now[500010];
signed main() {
srand(time(0));
int n,m,q;
scanf("%d%d",&n,&m);
long long nowsum=0,all=0;
for(int i=1;i<=n;i++) a[i]=rand(),all+=a[i];
for(int i=1;i<=m;i++) {
int x,y;
scanf("%d%d",&x,&y);
sum[y]+=a[x],now[y]+=a[x],nowsum+=a[x];
}
scanf("%d",&q);
while(q--) {
int op,x,y;
scanf("%d%d",&op,&x);
if(op==1||op==3) scanf("%d",&y);
if(op==1) now[y]-=a[x],nowsum-=a[x];
else if(op==2) nowsum-=now[x],now[x]=0;
else if(op==3) now[y]+=a[x],nowsum+=a[x];
else nowsum+=sum[x]-now[x],now[x]=sum[x];
if(nowsum==all) puts("YES");
else puts("NO");
}
return 0;
}
D. 数据传输
题意:给你一个树,第 $i$ 个点有点权 $v_i(>0)$,定义一次跳跃是合法的,当且仅当跳跃的两个节点的距离不超过 $k$。每次询问给出两个节点 $s,t$,你需要考虑一个从 $s$ 走到 $t$ 的方案 $s\to c_1\to c_2\to\cdots\to t$ 使得每步跳跃都合法。输出经过的点的最小点权和(即 $\min\limits_c\{s+\sum c+t\}$)。$n,q\le 2\times 10^5,k\le 3$。
首先考虑最简单的 $k=1$ 的情况。此时每步跳跃只能沿着边走,所以答案即为路径上的点权和。可以使用 LCA 和树上差分计算。
对于 $k=2$,我们可以把路径拉出来,每次跳一步或跳两步,通过简单的 $O(n)$ DP 来计算答案(虽然复杂度不可行)。考虑这个做法的正确性:一定是在两点间路径上跳吗?答案是一定的。如果不在两点间路径上跳,情况一定如下图:
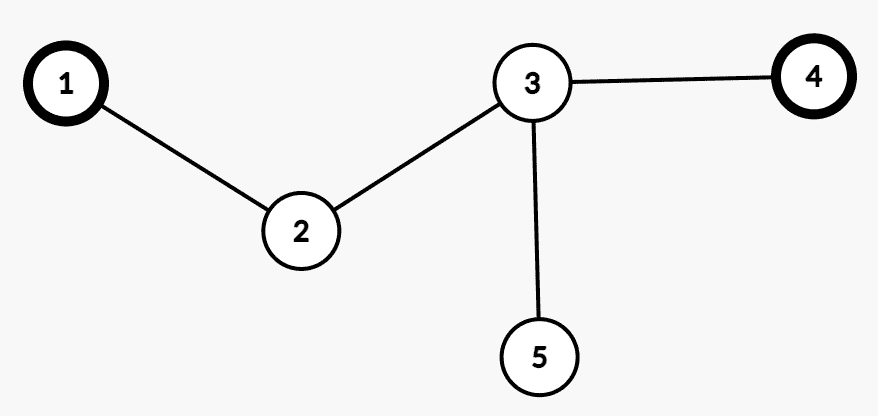
我们可以从 $2$ 跳到 $5$ 再跳到 $4$,但这样一定不如从 $2$ 直接跳到 $4$ 优。
对于 $k=3$,情况就变得麻烦多了。此时跳到路径外变得可行了,如下图:
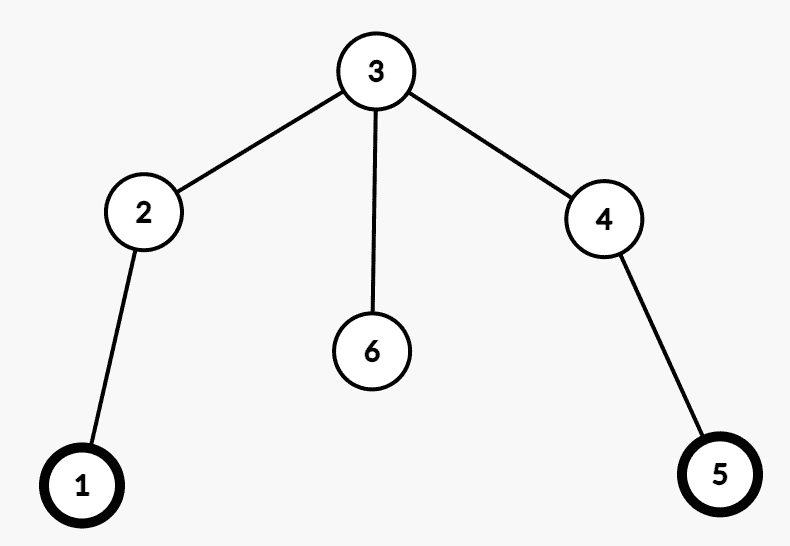
此时如果点 $6$ 的权值比 $2,3,4$ 小,那么最优策略将是 $1\to 6\to 5$。这就导致了我们上一节的 DP 变得不可行。我们考虑加强上面的过程。这次不只是单独把这一条链拉出来,还要把这条链周围一格的点也拉出来一起考虑。容易证明,这条链周围两格的节点是没有考虑的意义的,证明与上面 $k=2$ 链外无意义类似。
然后我们考虑扩展 DP 状态:定义 $f[i][j\in\{0,1,2\}]$ 表示只考虑链上前 $i$ 个点及其周围一格的点,而当前跳到了一个距离 $i$ 为 $j$ 的点上的最小代价。接着考虑转移:
$f[i][0]$。此时就在第 $i$ 个节点本身。可以从第 $i-1$ 个节点本身转移而来,也可以从“与第 $i-1$ 个节点距离为 $1$ 的节点”转移而来(此时需要跳两格),也可以从“与第 $i-1$ 个节点距离为 $2$ 的节点”转移而来(此时需要跳三格)。故:$f[i][0]=\min(f[i-1][0]+v_i,f[i-1][1]+v_i,f[i-1][2]+v_i)$。
$f[i][1]$。此时我们在“与第 $i$ 个节点距离为 $1$ 的节点”上。这有哪些可能性呢?如下图:

此时当前所在的位置有 $i-1,a,b,i+1$ 四种可能性。对于在 $i-1$ 的情况,可以由 $f[i-1][0]$ 转移过来(即保持不动);对于其他情况,我们只能从 $c$ 或 $i-2$(与 $i-1$ 距离为 $1$ 的点)转移,而不能从 $i-1$ 本身转移。这是因为,如果我们从 $i-1\to a$,下一步往上跳一格后往右至多跳两格,而此时可以直接从 $i-1$ 跳三格过去更优,所以不应从 $i-1\to a$。综上,$f[i][1]=\min(f[i-1][0],f[i-1][1]+mn_i)$,其中 $mn_i$ 为 $i$ 节点的邻居中最小的点权(都在 $i$ 周围的点没有本质区别,自然权值越小越好)。$mn$ 可以预处理出来。
$f[i][2]$。此时在 $c$ 或 $i-2$,距离 $i-1$ 为 $1$,所以直接由 $f[i-1][1]$ 转移而来。$f[i][2]=f[i-1][1]$。
结合以上分析,我们得到了如下的 DP 方程:
$$
\begin{aligned}
f[i][0]&=\min(f[i-1][0]+v_i,f[i-1][1]+v_i,f[i-1][2]+v_i)\
f[i][1]&=\min(f[i-1][0],f[i-1][1]+mn_i)\
f[i][2]&=\min(f[i-1][1])
\end{aligned}
$$
(最后一个为了统一格式也用 $\min$)容易发现,$f[i]$ 的三个状态完全由 $f[i-1]$ 的三个状态以及其他仅与 $i$ 有关的贡献转移而来。我们可以想到使用矩阵来优化这一步骤。我们新定义一个矩阵乘法:$[A\cdot B]{i,j}=\min\limits_k\{A{i,k}+B_{k,j}\}$。此矩阵乘法同样具有结合律:
$$
\begin{aligned}
[A\cdot (B\cdot C)]{i,j}&=\min\limits_k\{A{i,k}+[B\cdot C]{k,j}\}\
&=\min\limits_k\left\{A{i,k}+\min\limits_p\{B_{k,p}+C_{p,j}\}\right\}\
&=\min\limits_k\left\{\min\limits_p\{A_{i,k}+B_{k,p}+C_{p,j}\}\right\}\
&=\min\limits_p\left\{\min\limits_k\{A_{i,k}+B_{k,p}+C_{p,j}\}\right\}\
&=\min\limits_p\left\{\min\limits_k\{A_{i,k}+B_{k,p}\}+C_{p,j}\right\}\
&=\min\limits_p\{[A\cdot B]{i,p}+C{p,j}\}\
&=[(A\cdot B)\cdot C]_{i,j}
\end{aligned}
$$
这是一个经典的矩阵乘法的定义:内层相加,外层极值。于是,我们可以把 DP 转移转化为下面的矩阵乘法:
$$
\begin{bmatrix}
f[i][0] & f[i][1] & f[i][2]
\end{bmatrix}
\begin{bmatrix}
f[i-1][0] & f[i-1][1] & f[i-1][2]
\end{bmatrix}
\cdot
\begin{bmatrix}
v_i & 0 & +\infty\
v_i & mn_i & 0\
v_i & +\infty & +\infty
\end{bmatrix}
$$
在 $k=2$ 时也类似,转移矩阵稍微改变一下即可。将 DP 变为矩阵的转化直接使得在每个点的转移变得独立,而与具体路径完全无关。
由于结合律,问题转化为求路径上每个节点的矩阵乘积。由于树上的路径可以分为向上的一段和向下的一段,我们考虑倍增求树上 ST 表。定义 $g[i][j]$ 为一个矩阵,表示从第 $i$ 个点开始,往上连续 $2^j$ 个点的矩阵乘积,可以在预处理 LCA 时顺便完成 $g$ 的预处理。同时,定义 $h[i][j]$ 与 $g[i][j]$ 类似,只不过保存的是从上往下乘的结果。最终答案即为向上的总转移矩阵乘向下的总转移矩阵,再乘 $s$ 时的初始状态,使用树上倍增即可。时间复杂度 $qn\log(n)\times k^3$。
#include<bits\/stdc++.h>
using namespace std;
#define int long long
int n,q,k,v[200010];
struct matrix {
int n,a[3][3];
matrix operator*(matrix o) {
matrix res;
res.n=n;
for(int i=0;i<n;i++)
for(int j=0;j<n;j++) {
res.a[i][j]=1e18;
for(int k=0;k<n;k++)
res.a[i][j]=min(res.a[i][j],a[i][k]+o.a[k][j]);
}
return res;
}
} f[200010][20],g[200010][20];
vector<int> e[200010];
int fa[200010][20],mn[200010],dep[200010];
void dfs(int now,int father,int depth) {
fa[now][0]=father,dep[now]=depth;
f[now][0].n=k;
auto &t=f[now][0].a;
for(int i=0;i<3;i++)
t[i][0]=v[now];
t[0][1]=t[1][2]=0;
t[1][1]=mn[now];
t[2][1]=t[0][2]=t[2][2]=1e18;
if(k==2) t[1][1]=1e18;
g[now][0]=f[now][0];
for(int to:e[now])
if(to!=father) dfs(to,now,depth+1);
}
int LCA(int x,int y) {
if(dep[x]<dep[y]) swap(x,y);
for(int i=19;i>=0;i--)
if(dep[fa[x][i]]>=dep[y])
x=fa[x][i];
if(x==y) return x;
for(int i=19;i>=0;i--)
if(fa[x][i]!=fa[y][i])
x=fa[x][i],y=fa[y][i];
return fa[x][0];
}
signed main() {
memset(mn,0x3f,sizeof(mn));
scanf("%lld%lld%lld",&n,&q,&k);
matrix init;
init.n=k;
for(int i=0;i<k;i++)
for(int j=0;j<k;j++)
init.a[i][j]=(i!=j)*1e18;
for(int i=1;i<=n;i++)
scanf("%lld",&v[i]);
for(int i=1;i<n;i++) {
int x,y;
scanf("%lld%lld",&x,&y);
e[x].push_back(y);
e[y].push_back(x);
mn[x]=min(mn[x],v[y]);
mn[y]=min(mn[y],v[x]);
}
dfs(1,0,1);
for(int x=0;x<=19;x++)
f[0][x]=g[0][x]=init;
for(int j=1;j<=19;j++)
for(int i=1;i<=n;i++) {
fa[i][j]=fa[fa[i][j-1]][j-1];
f[i][j]=f[i][j-1]*f[fa[i][j-1]][j-1];
g[i][j]=g[fa[i][j-1]][j-1]*g[i][j-1];
}
while(q--) {
int s,t;
scanf("%lld%lld",&s,&t);
int lca=LCA(s,t),x=v[s];
s=fa[s][0];
matrix tmp1=init,tmp2=init;
for(int i=19;i>=0&&s;i--)
if(dep[fa[s][i]]+1>=dep[lca])
tmp1=tmp1*f[s][i],s=fa[s][i];
for(int i=19;i>=0&&t;i--)
if(dep[fa[t][i]]>=dep[lca])
tmp2=g[t][i]*tmp2,t=fa[t][i];
matrix ans=tmp1*tmp2;
printf("%lld\n",ans.a[0][0]+x);
}
return 0;
}