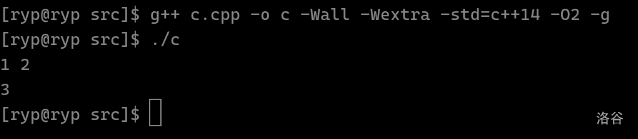
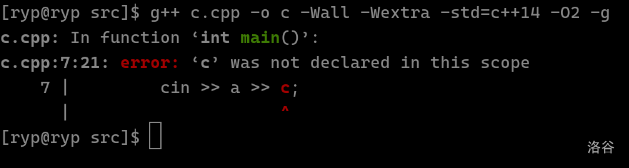
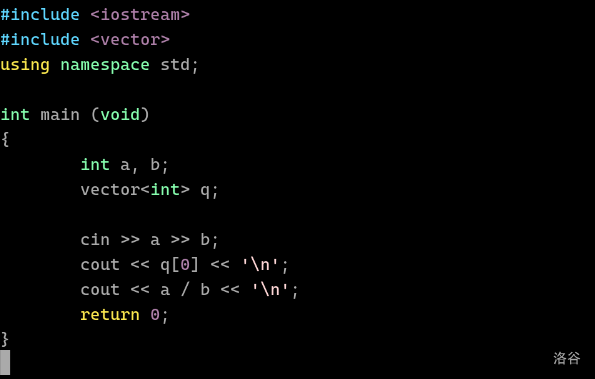
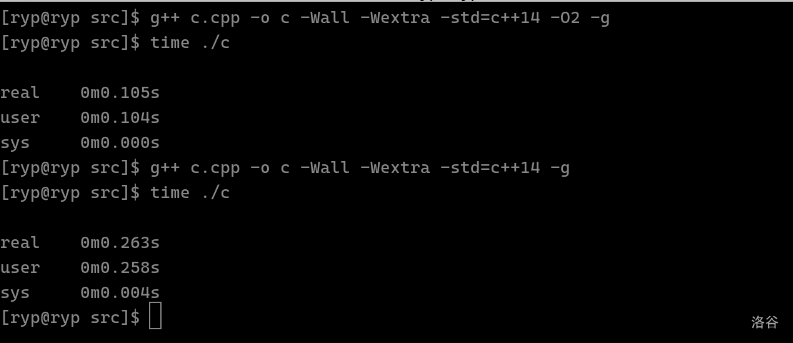
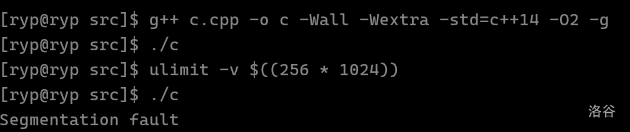
本文章由 WyOJ Shojo 从洛谷专栏拉取,原发布时间为 2024-07-06 16:00:32
0-1 Linux 使用
0-1-1.5 时间复杂度分析
0-2 初赛复习
第一节 进制基础
本文转自 https:\/\/blog.csdn.net\/qq_20013653\/article\/details\/137296081,如有侵权,请联系删除。
基础知识
进制也就是进位计数制,是人为定义的带进位的计数方法,可以用有限的数字符号代表所有的数值,可使用的数字符号的数目称为基数或底数,基数位n,即可称n进位制,简称n进制。
对于任何一种进制——X进制,每一位置上数的运算都是逢X进一位。十进制是逢十进一,十六进制是逢十六进一,二进制就是逢二进一,以此类推,X进制就是逢X进一。
任何一个数都可以用不同的进位制来表示。比如十进制数$57_{10}$,可以用二进制表示为$111001_{2}$,也可以用八进制表示为$71_8$,用十六进制表示为$39_{16}$,它们所表示的数值都是一样的。
十进制
- 基数为10,数码由0~9组成,计数规律为逢十进一。
- 对于十进制数可以不加标注,或加后缀D,其中D是十进制英文Decimal的首字母,如57、57D。
二进制
- 基数为2,数码由0、1组成,计数规律为逢二进一。
- 二进制数的书写通常在数的右下方注上基数2,或在后面加B表示,其中B是二进制英文Binary的首字母,如$111001_2$、$111001B$。
在计算机领域,我们之所以采用二进制进行计数,是因为二进制具有以下优点: - 二进制数中只有两个数码0和1,可以用具有两个不同稳定状态的元器件来表示。例如,电路中某一通路的电流的有无、某一节点电压的高低、晶体管的导通和截止等。
- 二进制数运算简单,大大简化了计算中运算部件的结构
- 二进制天然兼容逻辑运算
八进制
由于二进制的基数较小,数据的书写和阅读不方便,为此,在小型机中引入了八进制。
- 基数为8,数码由0~7组成,计数规律为逢八进一
- 八进制用下标8或在数据后面加O(Octal的首字母)表示,如718、71O。
- 在C++语言中,以数字0开头表示该数字是八进制数,如
cout<<071;。
十六进制
由于二进制的位数太长,不容易记忆,所以十六进制数就出现了。
- 基数为16,数码由0~9 加上A~F组成(A表示10),计数规律为逢十六进一。
- 十六进制用下标16或在数据后面加H(Hex的首字母)表示,如3916、39H。
- 在C++语言中,以前缀0x开头表示该数字是十六进制数,如
cout<<0x39;。
更大的进制则从F表示15开始,继续类推到Z,最大可以表示三十六进制。
赛题训练
1.二进制数00101100和00010101的和为( )。
A.00101000 B.01000001
C.01000100 D.001110002.在计算机内部用于传送、存储、加工处理的数据或指令都是以( )形式存在的。
A.二进制码 B.八进制码
C.十进制码 D.智能拼音码
第二节 进制转换
基础知识
十进制转二进制
除二取余法: 用2连续除十进制整数,直到商为0,逆序排列余数即可得到该十进制数的二进制表示。
例如十进制57转为二进制数:
- 57除以2得28余1
- 28除以2得14余0
- 14除以2得7余0
- 7除以2得3余1
- 3除以2得1余1
- 1除以2得0余1(商为0,结束)
逆序排列余数(从下往上)得到二进制数:111001B。
十进制整数转n进制同理,即除n取余法。
二进制数转十进制
按位权展开: 在数制中,各位数字所表示值的大小不仅与该数字本身的大小有关,还与该数字所在的位置有关,我们称其为数的位权, 简称权。
对于形式化的进制表示,我们可以从0开始,对数字的各个数位进行编号,即从个位起向左依次编号为0、1、2、…;对称的,小数点后的数位则是-1、-2、…。
如下表为二进制数111001.000B的位权表示:
| 位权 | 25 | 24 | 23 | 22 | 21 | 20 | 2\-1 | 2\-2 | 2\-3 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 数值 | 1 | 1 | 1 | 0 | 0 | 1 | . | 0 | 0 | 0 |
任意R进制数按权展开,相加即可得到十进制数,如二进制数111001B转为十进制数:
1×25+1×24+1×23+0×22+01+1×20\=57
其他进制数转十进制数同理,十进制数的位权是以10为底的幂,二进制数的位权是以2为底的幂,十六进制数的位权是以16为底的幂。数位由高向低,以降幂的方式排列。
进制快捷转换
由于2的3次方是8,所以二进制树转为八进制数时,可三个数一组进行转换(优先满足右侧分组,左侧最高位不够可以补零),每组内位权编号重新从零开始计算。例如,二进制数111001B转为八进制数:
(111)(001)B=(1×22+1×21+1×20)(0×22+0×21+1×20)O=71O
同理,由于2的4次方是16,二进制数转为十六进制数时,可四个数一组进行转换(优先满足右侧分组,左侧最高位不够可以补零),如二进制数111001B转为十六进制数:
(11)(1001)B=(1×21+1×20)(1×23+0×22+0×21+1×20)H=39H
其他进制间转换时,若进制存在幂运算关系,也可以此方法进行快捷转换。
十进制小数转二进制小数
乘二取整法: 用2乘十进制小数,可以得到积,将积的整数部分去除,再用2乘余下的小数部分,如此循环,将每步取出的整数部分顺序排列,得到小数的二进制表示。
整数部分用除二取余法得到二进制整数,小数部分用乘二取整法得到二进制小数。例如,十进制数32.12转为二进制数的步骤如下:
- 整数部分为32,小数部分为0.12
- 整数部分32除二取余法得到二进制数100000。
- 小数部分:
0.12×2=0.24取整数0
0.24×2=0.48取整数0
0.48×2=0.96取整数0
0.96×2=1.92取整数1(后续运算因数变为0.92)
0.92×2=1.84取整数1
0.84×2=1.68取整数1
(此时会发现,有的数的小数部分乘二取整法可能会无线运算下去,这时须按照题目精度要求截取足够位数即可)
顺序排列取出整数,得到小数部分二进制数为.000111。 - 结合得到最终二进制数为100000.000111。
总结:整数部分,除二取余,逆序排列;小数部分,乘二取整,顺序排列。
赛题训练
- 二进制数1011转换成十进制数是( )。
A.11 B.10 C.13 D.12 - 下列四个不同进制的数中,与其他三项数值不相等的是( )。
A.(269)16 B.(617)10 C.(1151)8 D.(1001101011)2 - 请选出以下最大的数( )。
A.(550)10 B.(777)8 C.210 D.(22F)16 - 十进制小数13.375对应的二进制数是( )。
A.1101.011 B.1011.011 C.1101.101 D.1010.01 - 与二进制小数0.1相等的八进制数是( )。
A.0.8 B.0.4 C.0.2 D.0.1 - 与二进制小数0.1相等的十六进制数是( )。
A.0.8 B.0.4 C.0.2 D.0.1 - 下面有四个数据组,每个组各有三个数据,其中第一个数据为八进制数,第二个数据为十进制数,第三个数据为十六进制数。这四个数据组中三个数据的是( )
A.120 82 50 B.144 100 68 C.300 200 C8 D.1762 1010 3F2
第三节 位运算
基础知识
程序中的所有数在计算机内存中都是以二进制的形式存储的,位运算就是直接对整数在内存中的二进制位进行操作(补码和符号位也参与运算,后面再补充补码的知识),如果是十进制数间进行位运算,则将十进制数先转换成二进制数再运算。位运算符及其运算规则如下:
按位与(&)
两个都是1才是1.例如:
00101 5
11100 28
&------------------------
00100 4
&运算通常用于二进制数的取位操作,例如一个数“&1”的结果就是取二进制数的最末位。这可以用来判断一个整数的奇偶性,二进制的最末位为0表示该数为偶数,最末位为1表示该数是奇数。对于一个数a,a=a&(a-1)的作用是将a的二进制数最右边的1变为0。
按位或(|)
只要有一个为1就为1。例如:
00101 5
11100 28
|------------------------
11101 29
|运算通常用于二进制数特定位上的无条件复制,例如一个数“|1”的结果就是把二进制最末位强行变成1.如果需要把二进制数最末位变成0,对这个数“|1”之后再减一就可以了,其实际意义就是把这个数强行变成最接近的偶数。
按位异或(^)
相同为0,不同为1(可以理解为“半加”,也就是不进位的二进制数加法)。例如:
00101 5
11100 28
^------------------------
11001 25
^运算可以用于简答的加密,比如我的某个密码是123456,但又担心密码被泄露,所以我使用19960706作为秘钥,123456 ^ 19960706= 20017602,我就把20017602记下来,等要使用密码时再计算20017602 ^ 19960706 = 123456,就得到我的密码了。
加法的逆运算是减法,乘法的逆运算是除法,^运算的逆运算是它本身。由此可以写出不需要中间变量的swap(交换两个数)过程。
int a = 10,b = 5;
\/\/借助中间量交换
int t = a;
a = b;
b = t;
\/\/借助互逆运算交换
a = a + b;
b = a - b;
a = a - b;
\/\/借助^交换
a = a ^ b;
b = a ^ b;
a = a ^ b;
注意:^的交换方法不能用于一个数的自我交换,会导致数据变为0。(大家可以自己去检验)
按位取反(~)
单目运算符,1变成0,0变成1,例如:
00101 5
~ ------------------
11010 -6
注意11010为补码。
使用~运算时要格外小心,需要注意整数类型有没有符号。如果 ~的对象是无符号整数(unsigned),那么得到的值就是它与该类型上界的差。
左移(<<)
a<<b就表示a转为二进制后左移b位(在后面添加b个0)。例如10的二进制数为1100100,而110010000转成十进制数是400,那么100<<2=400。可以看出a<<b的值实际上就是a乘以2的b次方,因为在二进制数后面添加一个0就相当于该数乘以2。
通常认为a<<1比a\*2更快,因为前者是更底层的一些操作。因此程序中乘以2的操作可以考虑用左移一位来代替。
定义一些常量可能会用到<<运算。你可以使用1<<16-1来表示65535。很多算法和数据结构要求数据规模必须是2的幂,此时可以用<<来定义MAX\_N等常量。
右移(>>)
与<<相似,a>>b表示把a转为二进制数后右移b位,低位舍弃b位,高位补b位符号位(正数补0、负数补1)。
右移运算对于正数,相当于a除以2的b次方(取商),用>>代替除法运算可以使程序效率大大提高。
位运算符优先级

速记:从高到低,反、(四则运算)、移、与、异、或。
赛题训练
- 二进制数11101110010111和01011011101011进行逻辑或运算的结果是( )。
A.11111111011111 B.11111111111101
C.10111111111111 D.11111111111111 - 二进制数11101110010111和01011011101011进行逻辑与运算的结果是( )。
A.01001010001011 B.01001010010011
C.01001010000001 D.01001010000011 - 为了统计一个非负整数中二进制形式中1的个数,代码如下:
int CountBit(int x){
int ret = 0;
while(x)
{
ret++;
________;
}
return ret;
}
A.x>>=1 B.x&=x-1
C.x|=x>>1 D.x<<=1
4\. 二进制数00101100和01010101异或的结果是( )。
A.00101000 B.01111001
C.01000100 D.00111000
第四节 存储单位
基础知识
存储单位是一种计量单位,指在某一领域以一个特定量或标准作为一个计数点,再以此点的某个倍数去定义另一个点,而这个点的代名词就是计数单位或存储单位。如货车的载重量是吨,也就是说这辆货车能存储货物的单位量词是吨。
二进制序列用以表示计算机、电子信息数据容量的量纲,基本单位为字节(B),字节单位的量级为1024,比如1KB=1024B、1MB=1024KB。
计算机存储单位一般用bit、B、KB、MB、GB、TB、PB等来表示,之间的关系如下:
- bit(b,位):读作比特,存放一个二进制数,即0和1,是最小的存储单位。
- Byte(B,字节):8个二进制位为一字节,即1B=8bit,是最常用的单位。
- Kilo Byte(KB):1KB=1024B。
- Mega Byte(MB):1MB=1024KB。
- Giga Byte(GB):1GB=1024MB。
- Tera Byte(TB):1TB=1024GB。
在C++中,基本变量类型所占的内存空间大小由计算机操作系统(32位和64位)和编译器决定。一般情况,各类型所占的存储空间和能表示的范围如下表所示。
| 数据类型 | 字节 | 取值范围 |
|---|---|---|
| char | 1 | \-128~127 |
| unsigned char | 1 | 0~255 |
| int | 4 | \-2147483648~2147483647 |
| unsigned int | 4 | 0~4294967295 |
| long long | 8 | \-9,223,372,036,854,775,808 ~9,223,372,036,854,775,807 |
| float | 4 | +/- 3.4e +/- 38 (7 位有效数字) |
| double | 8 | +/- 1.7e +/- 308 (15 位有效数字) |
在实际问题中,若long long都不足以满足需求,则要考虑使用数组来存放高精度数据,再重新定义高精度数据的四则运算。在信奥赛中,对高精度数据的处理也是常考项。
赛题训练
- 一个32位整型变量占用( )字节。
A.32 B.128 C.4 D.8 - 1MB等于( )。
A.1000字节 B.1024字节 C.1000×1000字节 D.1024×1024字节 - 计算机存储数据的基本单位是( )。
A.bit B.Byte C.GB D.KB
第五节 整数存储
基础知识
计算机中整数数值的存储并不是简单的将其转为二进制存入内存,因为涉及到正负数、减法运算等问题,所以科学家们设计了一套整数的存储规则–三码。
原码
整数存储的时候,用最高位表示符号(0为正数,1为负数),后面几位存储二进制数值,如:
| 正数 | 二进制 | 负数 | 二进制 |
|---|---|---|---|
| 0 | 0000 | \-0 | 1000 |
| 1 | 0001 | \-1 | 1001 |
| 2 | 0010 | \-2 | 1010 |
我们会发现一个问题,我们计算-1+1的结果时,得到的是1001+0001=1010,结果是-2。所以就有了反码。
反码
负数的二进制使用反码:符号位不变,其他相反。
| 正数 | 二进制 | 负数 | 二进制 |
|---|---|---|---|
| 0 | 0000 | \-0 | 1111 |
| 1 | 0001 | \-1 | 1110 |
| 2 | 0010 | \-2 | 1101 |
现在-1+1的结果是0001+1110=1111,等于-0。但是,0通常被认为是不具有正负之分的,所以又有了补码。
补码
负数的补码是用反码+1。
| 正数 | 二进制 | 负数 | 二进制 |
|---|---|---|---|
| 0 | 0000 | \-0 | 0000 |
| 1 | 0001 | \-1 | 1111 |
| 2 | 0010 | \-2 | 1110 |
现在我们的加法运算就完美了,0也没有分正负。
总结
- 正数的原码、反码、补码都死它本身。
- 负数的反码为原码(除符号位)取反,补码为反码加一。
- 计算机内存中存储的是补码。
- 因为存储的是补码,所以存储范围中的负数总比正数多一个(-0的原码被用来表示最小的负数)。
赛题训练
- 在8为二进制补码中,10101011表示的数是十进制下的( )。
A.43 B.-85 C.-43 D.-84 - 在字长为16位的系统环境下,一个16位带符号整数的二进制补码位1111111111101101。其对应的十进制整数应该是( )。
A.19 B.-19 C.18 D.-18
第六节 字符存储
基础知识
ASCII码表
计算机只能处理数字,那么如果要处理文本等信息,就必须先转换为数字才能处理。美国首先推出了ASCII(美国信息交换标准代码)码表,统一规定了常用的符号(使用7个bit,最多表示128位)。
对于ASCII码表,我们不需要记住每个字符的编号,只需要重点记住数字0的编码是48,大写字母A的编码是65,小写字母a的编码是97。因为剩余的数字和字母都是连续的,比如数字9的编码是57,大写字母Z的编码是90,小写字母z的编码是122,所以我们可以自己算出其他数字或字母的编码。
其他编码
ASCII码表能够解决英文字母、数字和一些符号的存储问题,但是全世界的语言有很多种,各国也有自己的编码方式,比如中文编码有用GB2312,繁体中文是BIG5,日文是Shift\_JIS,韩文是Euc\_kr等,这就会导致在多语言的混合文本中,显示会出现乱码。
因此就有了Unicode(万国码),将世界所有的符号都纳入其中,现在又一百多万个符号(前128个仍然是ASCII字符)。
但是ASCII编码是1字节,Unicode编码通常是2字节。如果我们都统一用Unicode虽然解决了乱码问题,但是用Unicode编码比ASCII编码至少多一倍的存储空间。所以Unicode也有多种存储方式,其中UTF-8(一种可变长的编码存储方案)比较常见,它会根据不同大小编码成1 ~ 6字节,比如英文字母编码成1字节,汉字通常是3字节,复杂一点的编码成4 ~ 6字节。
字符串
在C++语言中,字符类型变量位char,若以字符串(多个连续字符)的形式出现,则借助char数组或者string来存储,以下是一些与字符串相关的名词。
字典序:一般而言,若要对两个字符串做大小比较,那么比较规则就是按字典序,字符大小即为ASCII码表编号的大小。先比较第一个字符,如果一样就比较下一个字符…。如果不一样长比如(abc和abcd),那么短的在前,长的在后。
子串:字符串中任意个连续的字符组成的子序列称为该串的子串,空串和字符串本身也是该字符串的字串。
子序列:和子串不同,子序列不要求字符连续。
赛题训练
- 以下关于字符串的判定语句中正确的是( )。
A.字符串是一种特殊的线性表
B.串的长度必须大于零
C.字符串不可以用数组来表示
D.空格字符串组成的串就是空串 - ( )是一种通用的字符编码,它为世界上绝大部分语言设定了统一并且唯一的二进制编码,以满足跨语言、跨平台的文本交换,目前它已经收录了超过十万个不同字符。
A.ASCII B.Unicode C.GB2312 D.BIG5 - 字符串的子串是其连续的局部,字符串自身是其最长的子串,空串是其最短的子串,对于字符串S=“Microsoft”,其非空子串的个数是( )。
A.72 B.46 C.45 D.36 - 若串S=“copyright”,其子串的个数是( )。
A.72 B.45 C.46 D.36 - 下列字符中,ASCII码值最小的是( )。
A.a B.B C.R D.1
第七节 图像存储
基础知识
计算机的数字化图像数据有两种存储方式:位图(Bitmap)存储和矢量(Vector)存储。
像素:整个图像中不可分割的最小单位或元素。它以一个单一颜色的小方格存在,所有小方格的颜色和位置的组合决定了该图像呈现出来的样子。
图像的位分辨率:也叫位深,用来衡量每个像素存储信息的位数,决定了多少种色彩等级的可能性,所以有时又将位分辨率称为颜色深度。常见的有8位、16位、24位、32位、64位色彩,即二进制数的位数,如24位色彩能组合出224\=16777216种色彩等级。
屏幕分辨率:指屏幕上显示的像素的个数,如1024×768的分辨率指屏幕上水平方向有1024个像素点,垂直方向上有768个像素点。
像素点距:指显示屏相邻两个像素点之间的距离,画质的细腻度就是由点距来决定的,点距越小,图像越细腻。
位图存储
由一系列像素组成的可识别图像。如果把一幅位图看成一个二维数组,则数组中的任一元素(即像素)对应于图像中的一个点,而存储的值对应于该点的颜色或者灰度。
特性:位图图像是由数目固定像素组成的图像
第八节 浮点数存储
基础知识
(浮点数存储在CSP竞赛中还未出现过,如果有遗漏欢迎指正,这部分仅供拓展知识用)
小数:实数的一种特殊的表现形式,所有分数都可以表示成小数。
纯小数:整数部分是零的小数。
带小数:整数部分不是零的小数。
顶点数:指小数点在数中的位置是固定不变的,有定点整数和定点小数。
浮点数:小数点的位置不是固定的,用阶码和尾数表示。通常尾数为小数,阶码为整数,尾数和阶码均为带符号数。尾数的符号表示数的正负,阶码的符号表示小数点的实际位置。浮点数的精度由尾数决定,数的表示范围由阶码决定。
浮点数的表现形式类似于数学中的科学计数法,表示为N=M×RE。
其中N是浮点数自身,M为尾数,R为该浮点数的进制,E为阶码。
如二进制小数10011.101,按浮点数形式表示为1.0011101×24。
其中尾数为+1.0011101,阶码为+4。
注意:浮点数不一定是小数,定点数也不一定是整数。
移码:即补码的符号位取反,如4为二进制数的移码:-1=0111,1=1001。
0111在十进制下是7,1001在十进制下是9,相当于给原数加了8(23)。
速算技巧:n位二进制数的移码相当于加上2n-1。
在C++中,存放浮点数的变量类型有float和double,分别占用32位和64位二进制数,空间分配规则如下:
| 符号位 | 指数位 | 尾数位 | |
|---|---|---|---|
| float | 1 | 8 | 23 |
| double | 1 | 11 | 52 |
以float类型为例,在32为二进制空间中,从左往右:
- 最高位用来表示正负(0为正数,1为负数)
- 中间8位指数位用来存放浮点数阶码(阶码的移码减1,速算偏移为127)
- 最后23位用来表示尾数部分(纯小数)
例如,十进制数19.625,以float类型存储,二进制数计算规则:
1、19.625转换为二进制数为10011.101,浮点数表示为1.0011101×24。
2、因为是正数,所以符号位为0。
3、阶码为+4,8为指数位的移码偏移为127(27\-1),4+127=131=10000011B。
4、尾数为1.0011101,由于所有浮点数的尾数都是1.××××的形式,所以可以将1舍去,只存储后面部分0011101.
三个部分合在一起,得到19.625在内存中的存储形式如下:
| 符号位(1) | 指数位(8) | 位数位(23) |
|---|---|---|
| 0 | 10000011 | 00111010000000000000000 |
如果是double类型存储,原理不变,只是指数位变为11位,对应的移码偏移为1023(210\-1)。
第九节 时空复杂度
基础知识
算法是解决问题的方案,对同一个问题可能会有多种算法,那么通常如何评价一个算法的好坏,我们有以下标准:
- 正确性:对合法输入、非法输入、边界输入都能够正确处理,输出合理的结果。
- 可读性:算法应该描述清晰,方便阅读、理解和交流。
- 健壮性:算法运行结果一致,对于相同的输入始终输出相同的结果。
- 高效性:算法应占用最少的CPU和内存来得到满足的结果,这一点从时间复杂度和空间复杂度进行判定。
简单来说就是:
- 时间效率: 算法运行有多快
- 空间效率: 内存占用有多少
但是运行时间和语言、机器和机器的状态、数据量的大小都有关系,无法准确衡量算法效率,所以通常用一个相对度量的概念来衡量。
时间复杂度
- 大T函数T(n)
假设其他状态不变,仅当问题规模(数据大小)增大时,指令执行的次数也在增加,那么指令执行次数相对于问题规模来说,会构成一个函数T(n)。
例如,对n个数求和的算法1+2+3+…+n:
int sum = 0; \/\/指令数为1
for(int i = 0; i < n; i++)
sum += n; \/\/指令数为n
cout << n; \/\/指令数为1
总的指令数为T(n) = n + 2。
大O函数O(n)
假设一个算法的T(n) = 4n3+2n+5。当n越来越大时,对于T(n)增长的贡献来看,最高阶的n3占据主导地位,其他项可以忽略。
我们一般用大O函数来表示最主要的贡献部分,O(T(n)) = O(n3),就是算法的时间复杂度。
大O函数的数学定义:存在正常数c和某个规模n0,如果对所有的n ≥ n0,都有f(n) ≤ cT(n),则称f(n)为T(n)的大O函数,写成f(n) = O(T(n))。
计算方法:对算法的指令次数进行计算组成T(n),只保留最高阶项,然后去掉最高阶前面的常数。常见大O函数
| 函数 | 名称 | 例子 |
|---|---|---|
| O(1) | 常数阶 | 交换算法 |
| O(log n) | 对数阶 | 二分查找算法 |
| O(n) | 线性阶 | 求和算法 |
| O(nlog n) | 线性对数阶 | 快速排序算法 |
| O(n2) | 平方阶 | 冒泡排序算法 |
| O(nc) | 多项式阶(c>1) | 多重循环的算法 |
| O(cn) | 指数阶 | 汉诺塔问题 |
| O(n!) | 阶乘阶 | 旅行商问题 |
- 代码示例
O(n):输出数组元素。
for(int i = 0; i < n; i++)
cout << a[n] << " ";
O(log n):给定n,求2的指数p,使得p ≤ n< 2p。
int p = 1;
while(p < n)
p *= 2;
cout << p;
$O(n^2)$:输出二维数组。
for(int i = 0; i < n; i++){
for(int j = 0; j < n; j++)
cout << a[i][j] << " ";
cout << endl;
}
O(nlog n):
for(int i = 0; i < n; i++)
for(int j = 0; j < n; j *= 2)
...
空间复杂度
空间复杂度是对一个算法在运行过程中临时占用存储空间大小的度量。
一个算法在计算机存储器上所占用的存储空间包括:
- 算法代码本身所占用的存储空间
- 算法的输入输出数据所占用的存储空间
- 算法在运行过程中临时占用的存储空间
其中,存储算法代码本身所占用空间与算法书写大的长短有关,要压缩这方面存储空间,就必须编写较短的代码。
输入输出数据所占用空间由要解决的问题决定的,不会随算法的不同而改变。
算法在运行过程中临时占用的空间会因算法的不同而异,有的算法只需要少量临时工作单元,而且不随问题规模大小而改变,是节省存储空间的算法;有的算法需要占用临时工作单元与解决问题的规模n有关,当n较大时,将占用较多的存储单元,比如归并排序。
我们在分析算法的空间复杂度时要从各方面综合考虑。比如递归算法,一般比较简短,算法本身占用空间较少,但运行时需要一个附加栈,从而占用较多临时工作单元;若写成非递归算法,代码一般较长,本身占用空间较多,但运行时所需的存储单元较少。
- S(n)
一个算法的空间复杂度只考虑在运行过程中为变量分配的存储空间的大小,记为S(n),包括
1)函数参数表中形参变量分配的存储空间
2)函数体中定义的局部变量分配的存储空间
若一个算法为递归算法,其空间复杂度为递归所使用的栈的空间大小,等于一次调用所分配的临时存储空间的大小乘以被调用的次数。 - 大O函数
与时间复杂度类似,算法的空间复杂度一般也以数量级的形式O(n)给出。
一般而言:
1)当一个算法的空间复杂度S(n)为一个常量,即不随被处理数据量n的大小而改变,可表示为O(1)。
2)当一个算法的空间复杂度S(n)与以2为底的n的对数成正比时,可表示为O(log n)。
3)当一个算法的空间复杂度S(n)与n成线性比例关系时,可表示为O(n)。
特殊的:
1)若形参为数组,则只需要为它分配一个用于存储由实参传送来的一个地址指针的空间,即 一个机器字长空间
2)若形参为引用方式,则也只需要为其分配用于存储一个地址的空间,即用它来存储对应实参变量的地址,以便由系统自动引用实参变量。
在竞赛中,内存限制一般为128MB(或256MB),都足够用了。
赛题训练
- 若某算法的计算时间表示为递推关系式:
T(N) = 2T(N / 2) + Nlog N
T(1)=1
则该算法的时间复杂度为( )。
A.O(N) B.O(Nlog N) C.O(Nlog2 N) D.O(N2) - 假设某算法的计算时间表示为递推关系式:
T(N) = 2T(N / 4) + sqrt(N)
T(1)=1
A.O(N) B.O(sqrt(N)) C.O(sqrt(N) log N) D.O(N2) - 设某算法的时间复杂度函数的递推方程是T(n) = T(n-1) + n(n为正整数)及T(0) = 1,则该算法的时间复杂度为( )。、
A.O(log n) B.O(nlog n) C.O(n) D.O(n$^2$)
第十节 十大排序
基础知识
十大排序是指将无序序列变为有序序列的十种常见排序算法,分别是:冒泡、选择、插入、快速、归并、希尔、堆、桶、基数、计数。
基础分类
排序方式:
1)比较类排序:
- 交换类:冒泡排序、快速排序
- 插入类:插入排序、希尔排序
- 选择类“选择排序、堆排序
- 归并类:归并排序
2)非比较类排序:基数排序、计数排序、桶排序。
排序思路:
我们这里以从小到大排序为例。
- 冒泡排序:两两比较、顺序不对就交换。
- 选择排序:左无序,右有序。找出无序部分中的最大值,放在最后(交换)。
- 插入排序:左有序,右无序。将无序部分第一个数往前移动,放在第一个比他小的数的后面。
- 快速排序:序列中选取基准值,然后分区(比基准值小的放在左侧,大的放在右侧),然后递归每个分区。
- 归并排序:先分后合,将两个小的有序部分合并为大的有序部分。
- 希尔排序:插入排序的增量可视为1,在某些极端情况下效率较差。希尔排序改为设立增量序列,按增量序列执行多次插入排序。
- 堆排序:无需部分构建大顶堆,根节点值最大,与最后一个节点交换,重复这个过程,类似于选择排序。
- 桶排序:通过映射函数将待排序数据分组,对每个组选择合适的排序算法排序后,遍历每个桶,依次赋值回原数组。
- 基数排序:设立0~9是个桶数组,待排序数按个位放入桶中,依次拿出,再按十位、百位,重复上述过程。
- 计数排序:借助数组下标有序,先存入数组并统计个数,再遍历赋值回原数组。
稳定性:
排序前如果有两个数a和b相等,a在b的前面,排序后a仍在b的前面,则该算法稳定;否则该算法不稳定。
稳定的排序:冒泡、插入、归并、计数、桶、基数
不稳定的排序:快速、堆、选择、希尔
时空复杂度:
(n表示待排序数据规模,k表示待排序数据范围,对数以2为底)
| 排序算法 | 时间复杂度(平均) | 时间复杂度(最好) | 时间复杂度(最差) | 空间复杂度 |
|---|---|---|---|---|
| 冒泡排序 | O(n2) | O(n) | O(n2) | O(1) |
| 选择排序 | O(n2) | O(n2) | O(n2) | O(1) |
| 插入排序 | O(n2) | O(n) | O(n2) | O(1) |
| 希尔排序 | O(n1.3~2) | O(n) | O(n2) | O(1) |
| 归并排序 | O(nlog n) | O(nlog n) | O(nlog n) | O(n) |
| 快速排序 | O(nlog n) | O(nlog n) | O(n2) | O(log n) |
| 堆排序 | O(nlog n) | O(nlog n) | (O(nlog n) | O(1) |
| 计数排序 | O(n + k) | O(n + k) | O(n + k) | O(k) |
| 桶排序 | O(n + k) | O(n + k) | O(n2) | O(n + k) |
| 基数排序 | O(nk) | O(nk) | O(nk) | O(n + k) |
赛题训练
- 排序的算法很多,若按排序的稳定性和不稳定性分类,则( )是不稳定排序。
A.冒泡排序 B.插入排序 C.快速排序 D.归并排序 - 以下排序算法中,不需要进行关键字比较操作的算法是( )。
A.基数排序 B.冒泡排序 C.堆排序 D.插入排序 - 以下排序算法中,最好情况下最快的是( )。
A.快速排序 B.冒泡排序 C.堆排序 D.归并排序 - 设A和B是两个长为n的有序数组,现在需要将A和B合并成一个排好序的数组。那么,任何以元素比较作为基本运算的归并算法,在最坏情况下至少要做多少次比较?( )
A.n2 B.nlog n C.2n D.2n - 1
第十一节 排列组合
基础知识
排列是指从给定个数的元素中取出指定个数的元素进行排序。
组合是指从给定个数的元素中仅仅取出指定元素个数的元素,不考虑排序。
排列组合问题的关键就是研究给定要求的排列和组合可能出现的情况的总数。
定义与公式
排列:从n个不同元素中,任取m(m≤n,均为自然数)个不同的元素按照一定的顺序排成一列,所有排列的个数,称作从n个元素中取出m个元素的排列数。用符号 A ( n , m ) A(n,m) A(n,m)或 A n m A^m\n Anm表示。计算公式如下:
A n m = n ! ( n − m ) ! A^m\_n=\frac{n!}{(n-m)!} Anm\=(n−m)!n!
组合:从n个不同元素中,任取m(m≤n)个元素并成一组,所有组合的个数,称作从n个元素中取出m个元素的组合数。用符号 C ( n , m ) C(n,m) C(n,m)或 C n m C^m\_n Cnm表示。计算公式如下:
C n m = A n m m ! = n ! m ! ( n − m ) ! C^m\_n=\frac{A^m\_n}{m!}=\frac{n!}{m!(n-m)!} Cnm\=m!Anm\=m!(n−m)!n!
基本计数原理
加法原理:做一件事,完成它可以有n类办法,在第一类办法中有m1种不同的犯法,在第二类办法中有m2种不同的方法…在第n类办法中有mn种不同的方法,那么完成这件事共有 N = m 1 + m 2 + . . . + m n N=m\{1}+m\{2}+...+m\{n} N\=m1+m2+...+mn种不同的方法。
乘法原理:做一件事,完成它需要分成n个步骤,做第一步有m1种不同的方法,做第二步有m2种不同的方法…做第n步有mn种不同的方法,那么完成这件事共有 N = m 1 × m 2 × . . . × m n N=m\{1}×m\{2}×...×m\_{n} N\=m1×m2×...×mn种不同的方法。
范例精讲
例1 从一个 4 × 4 4×4 4×4的棋盘中选取不在同一行也不在同一列上的两个方格,共有( )种方法。
A.60 B.72 C.86 D.64
【正确答案:B】
解析:对每个方格来说,与其不在同一行同一列的方格有 3 × 3 = 9 3×3=9 3×3\=9个,总共有 4 × 4 = 16 4×4=16 4×4\=16个方格,也就是会有 16 × 9 16×9 16×9种,但是会有重复的情况(A格和B格,B格和A格,是一种情况),所以有 16 × 9 ÷ 2 = 72 16×9÷2=72 16×9÷2\=72种。
例2 5个小朋友排成一列,其中有两个小朋友是双胞胎,如果要求这两个双胞胎必须相邻,则有( )种不同的排列方法。
A.48 B.36 C.24 D.72
【正确答案:A】
解析:我们可以把双胞胎先看成一个整体,则问题变成了4个人的排列问题,共有 A ( 4 , 4 ) = 24 A(4,4)=24 A(4,4)\=24种,然后两个双胞胎内部的排列有 A ( 2 , 2 ) = 2 A(2,2)=2 A(2,2)\=2种,所以共有 24 × 2 = 48 24×2=48 24×2\=48种。
例3 有5副不同颜色的手套(共10只手套,每副手套左右手各一只),一次性从中取6只手套,请问恰好能配成两副手套的不同取法有( )种。
A.120 B.180 C.150 D.30
【正确答案:A】
解析:首先确定两副凑成一对的手套颜色组合用 C ( 5 , 2 ) = 10 C(5,2)=10 C(5,2)\=10种。然后是不成一副手套的两个手套的选择,先确定颜色组合有 C ( 3 , 2 ) = 3 C(3,2)=3 C(3,2)\=3种取法,再分左右手,每种颜色下又有 C ( 2 , 1 ) = 2 C(2,1)=2 C(2,1)\=2种取法,总共 10 × 3 × 2 × 2 = 120 10×3×2×2=120 10×3×2×2\=120种。
例4 由数字 1 、 1 、 2 、 4 、 8 、 8 1、1、2、4、8、8 1、1、2、4、8、8所组成的不同的 4 4 4位数的个数是( )。
A.104 B.102 C.98 D.100
【正确答案:B】
解析:因为存在相同的值,不能一次性考虑完,需要分情况讨论。
- 1 、 2 、 4 、 8 1、2、4、8 1、2、4、8组成的 4 4 4位数: A ( 4 , 4 ) = 24 A(4,4)=24 A(4,4)\=24种。
- 1 、 1 、 2 、 4 、 8 1、1、2、4、8 1、1、2、4、8组成的 4 4 4位数(一定有两个 1 1 1):先从 2 、 4 、 8 2、4、8 2、4、8三个数种选两个,再除去两个 1 1 1内部的重复排列: C ( 3 , 2 ) × A ( 4 , 4 ) / A ( 2 , 2 ) = 36 C(3,2)×A(4,4)/A(2,2)=36 C(3,2)×A(4,4)/A(2,2)\=36种。
- 1 、 2 、 4 、 8 、 8 1、2、4、8、8 1、2、4、8、8组成的 4 4 4位数(一定有两个 8 8 8):同上,也有 36 36 36种。
- 1 、 1 、 8 、 8 1、1、8、8 1、1、8、8组成的 4 4 4位数:考虑两个 1 1 1和两个 8 8 8各自内部重复排列,共有 A ( 4 , 4 ) / ( A ( 2 , 2 ) × A ( 2 , 2 ) ) = 6 A(4,4)/(A(2,2)×A(2,2))=6 A(4,4)/(A(2,2)×A(2,2))\=6种。
总共: 24 + 36 + 36 + 6 = 102 24+36+36+6=102 24+36+36+6\=102种。
例5 设含有 10 10 10个元素的集合的全部子集数位 S S S,其中由 7 7 7个元素组成的子集数位 T T T,则 T / S T/S T/S的值为( )。
A. 5 / 32 5/32 5/32 B. 15 / 128 15/128 15/128 C. 1 / 8 1/8 1/8 D. 21 / 128 21/128 21/128
【正确答案:B】
解析:每个元素选入子集和不选入子集两种选择, 10 10 10个元素就有210\=1024种选择,即 S = 1024 S=1024 S\=1024。 T = C ( 10 , 7 ) = C ( 10 , 3 ) = 120 T=C(10,7)=C(10,3)=120 T\=C(10,7)\=C(10,3)\=120。 T / S = 120 / 1024 = 15 / 128 T/S=120/1024=15/128 T/S\=120/1024\=15/128。
相同与不同、空与不空问题
盒子不空:
- 5个不同的小球放入3个不同的盒子(每盒不空),一共有多少种放法?
C 5 2 C 3 2 A 2 2 A 3 3 + C 5 1 C 4 1 A 2 2 A 3 3 = 150 \frac{C^2\_5C^2\_3}{A^2\_2}A^3\_3+\frac{C^1\_5C^1\_4}{A^2\_2}A^3\_3=150 A22C52C32A33+A22C51C41A33\=150 - 5个不同的小球放入3个相同的盒子(每盒不空),一共有多少种放法?
C 5 2 C 3 2 A 2 2 + C 5 1 C 4 1 A 2 2 A = 25 \frac{C^2\_5C^2\_3}{A^2\_2}+\frac{C^1\_5C^1\_4}{A^2\_2}A=25 A22C52C32+A22C51C41A\=25 - 5个相同的小球放入3个不同的盒子(每盒不空),一共有多少种放法?
C 4 2 = 6 C^2\_4=6 C42\=6 - 5个相同的小球放入3个相同的盒子(每盒不空),一共有多少种放法?
1 + 1 = 2 1+1=2 1+1\=2
盒子可空:
- 5个不同的小球放入3个不同的盒子(可有空盒),一共有多少种放法?
3 5 = 243 3^5=243 35\=243 - 5个不同的小球放入3个相同的盒子(可有空盒),一共有多少种放法?
1 + C 5 1 + C 5 2 + C 5 2 C 3 2 A 2 2 + C 5 1 C 4 1 A 2 2 = 41 1+C^1\_5+C^2\_5+\frac{C^2\_5C^2\_3}{A^2\_2}+\frac{C^1\_5C^1\_4}{A^2\_2}=41 1+C51+C52+A22C52C32+A22C51C41\=41 - 5个相同的小球放入3个不同的盒子(可有空盒),一共有多少种放法?
C 7 2 = 21 C^2\_7=21 C72\=21 - 5个相同的小球放入3个相同的盒子(可有空盒),一共有多少种放法?
1 + 2 + 2 = 5 1+2+2=5 1+2+2\=5
赛题训练
- 10个三好学生名额分配到7个班级,每个班级至少有一个名额,一共有( )种不同的分配方案。
A.84 B.72 C.56 D.504 - 把8个同样的球放在5个同样的袋子里,允许有的袋子空着,共有( )种不同的分法。(提示:如果8个球都放在一个袋子里,无论是哪个袋子,都只算一种分法。)
A.22 B.24 C.18 D.20 - 将7个名额分给4个不同的班级,允许有的班级没有名额,有( )种不同的分配方案。
A.60 B.84 C.96 D.120 - 甲、乙、丙三位同学选修课程,从4门课程中,甲选修2门,乙、丙各选修3门,则不同的选修方案共有( )种。
A.36 B.48 C.96 D.192 - 有7各一模一样的苹果,放到3个一模一样的盘子中,一共有( )种放法。
A.7 B.8 C.21 D.37
第十二节 鸽巢原理
基础知识
“鸽巢原理”又称“抽屉原理”,是组合数学中一个重要的原理,最先由19世纪的德国数学家狄利克雷运用于解决数学问题,所以又称“狄利克雷原理”。
第一抽屉原理
原理1:把多于n个物体放到n个抽屉里,则至少有一个抽屉里的物体不少于两个。
原理2:把多于mn+1(n不为0)个物体放到n个抽屉里,则至少有一个抽屉里有不少于m+1个物体。
原理3:把无数个物体放入n个抽屉,则至少有一个抽屉里有无数个物体。
第二抽屉原理
把mn-1个物体放入n个抽屉,其中必有一个抽屉中至多有m-1个物体。
原理案例
- 把10个苹果任意放在9个抽屉里,则至少有一个抽屉里含有两个或两个以上的苹果。
- 一年有365天,现有366人,则至少有两个人同一天生日。
- 抽屉中有10双手套,从中取11只出来,其中至少有两只是完整配对的。
鸽巢原理的题目在解题过程中就是保证在不达成题目条件的情况下,尽可能地多取。
范例精讲
例1 5种颜色的袜子各15只混装在箱子里,试问无论如何取,从箱子中至少取出几只袜子,就能保证有3双袜子。(袜子无左右之分)
解析:首先保证不成对地取5只袜子,再取一只(6只)成第一对,再取刚刚成对的颜色的袜子(7只),保证不成对;再取一只成第二对(8只),同理,再取刚刚成对的颜色的袜子(9只),保证不成对;最后取一只(10只)成第三对,总共10只。
例2 有35个球,红、白、黄各10个,另外有3个蓝色、2个绿色,试问无论如何取,至少取几个小球就能保证有4个同色球。
解析:先取完蓝色和绿色(5个),再取红、白、黄各3个(14个),最后随便取一个(15),总共15个。
赛题训练
- 一副纸牌除去大小王共有52张牌,四种花色,每种花色13张。假设从这52张牌中随机取13张纸牌,则至少( )张牌的花色一致。
A.4 B.2 C.3 D.5
第十三节 容斥原理
基础知识
在计数时,必须注意没有重复,没有遗漏。为了使重叠部分不被重复计算,人们研究出一种新的计数方法,基本思想是:先不考虑重叠的情况,把包含于某内容中的所有对象的数目先计算出来,然后再把计数时重复计算的数目排斥除去,使得计算的结果既无遗漏又无重复,这种计数的方法称为容斥原理。
基本计算公式
∣ A ∪ B ∣ = ∣ A ∣ + ∣ B ∣ − ∣ A ∩ B ∣ | A\\cup B|=|A|+|B|-|A\\cap B| ∣A∪B∣\=∣A∣+∣B∣−∣A∩B∣
∣ A ∪ B ∪ C ∣ = ∣ A ∣ + ∣ B ∣ + ∣ C ∣ − ∣ A ∩ B ∣ − ∣ A ∩ C ∣ − ∣ B ∩ C ∣ + ∣ A ∩ B ∩ C ∣ | A\\cup B\\cup C|=|A|+|B|+|C|-|A\\cap B|-|A\\cap C |-|B\\cap C|+|A\\cap B\\cap C| ∣A∪B∪C∣\=∣A∣+∣B∣+∣C∣−∣A∩B∣−∣A∩C∣−∣B∩C∣+∣A∩B∩C∣
( A 、 B 、 C A、B、C A、B、C为集合, ∣ A ∣ |A| ∣A∣表示 A A A集合内成员数量, ∪ \\cup ∪运算为并集, ∩ \\cap ∩为交集)
范例精讲
例1 某班有学生45人,每人在暑假里都参加体育训练队,其中参加足球队的有25人,参加排球队的有22人,参加游泳队的有24人,足球、排球都参加的有12人,足球、游泳都参加的有9人,排球、游泳都参加的有8人,问:三项都参加的有多少人?
解析:设参加足球队的人数为A,参加排球队的人数为B,参加游泳队的人数为C,三项都参加的人数设为X。带入计算公式: 25 + 22 + 24 − 12 − 99 − 8 + X = 45 25+22+24-12-99-8+X=45 25+22+24−12−99−8+X\=45,解得 X = 3 X=3 X\=3。
例2 分母是1001的最简分数一共有多少个?
解析:此题实际是找分子中不能与1001进行约分的数。由于先对1001质因子分解,可知 1001 = 7 × 11 × 13 1001=7×11×13 1001\=7×11×13,所以就是找不能被 7 、 11 、 13 7、11、13 7、11、13整除的数。
在 1 1 1~ 1001 1001 1001中,是 7 7 7的倍数的有 1001 / 7 = 143 1001/7=143 1001/7\=143个;是 11 11 11的倍数的有 1001 / 11 = 91 1001/11=91 1001/11\=91个;是 13 13 13的倍数的有 1001 / 13 = 77 1001/13=77 1001/13\=77个;是 7 × 11 7×11 7×11的倍数的有 1001 / 77 = 13 1001/77=13 1001/77\=13个;
是 7 × 13 7×13 7×13的倍数的有 1001 / 91 = 11 1001/91=11 1001/91\=11个;是 11 × 13 11×13 11×13的倍数的有 1001 / 143 = 7 1001/143=7 1001/143\=7个;是 7 × 11 × 13 7×11×13 7×11×13的倍数的有 1001 / 1001 = 1 1001/1001=1 1001/1001\=1个。
代入容斥原理基本计算公式:能被7或11或13整除的数有 ( 143 + 91 + 77 ) − ( 13 + 11 + 7 ) + 1 = 281 (143+91+77)-(13+11+7)+1=281 (143+91+77)−(13+11+7)+1\=281个,所以不能被 7 、 11 、 13 7、11、13 7、11、13整除的数有 1001 − 281 = 720 1001-281=720 1001−281\=720个。
赛题训练
一次期末考试,某班有15个数学得满分,有12人语文得满分,并且有4人语、数都是满分,那么这个班至少有一门得满分得同学有多少人?( )
A.23 B.21 C.20 D.2210 000以内,与10 000互质得正整数有( )个。
A.2000 B.4000 C.6000 D.8000第十四节 概 率
基础知识
概率是反映随机事件出现的可能性大小。随机事件是指在相同条件下,可能出现也可能不出现的事件。设对某一随机现象进行了 n n n次实验与观察,其中 A A A事件出现了 m m m次,即其出现的频率为 m / n m/n m/n。经过大量反复实验,常有 m / n m/n m/n越来越接近与某个确定的常数。该常数即为事件A出现的概率,常用 P ( A ) P(A) P(A)表示。
如果一个实验满足以下两条:
1)实验只有有限个基本结果
2)实验的每个基本结果出现的可能性是一样的
此类实验被称作古典实验,对于古典实验中的事件 A A A,它的概率定义为 P ( A ) = m / n P(A)=m/n P(A)\=m/n。其中 n n n表示该实验中所有可能出现的基本结果的总数目。 m m m表示事件 A A A包含的实验基本结果数,这种定义概率的方法称为概率的古典定义。
事件
在一个特定的随机试验中,称每一个可能出现的结果为一个基本事件,全体基本事件的集合称为基本空间,事件可分为以下几类:
- 必然事件:实验中必定会发生的事件。
- 随机事件:在一定的条件下可能发生也可能不发生的事件。
- 互斥事件:不可能同时发生的两个事件。
- 对立事件:两个事件中必有一个发生的互斥事件。
期望
是实验中每次可能出现的结果的概率乘以该结果的总和。反映了随机变量平均取值的大小。
举例说明:某城市有10万个家庭,没有孩子的家庭有1000个,有一个孩子的家庭有9万个,有两个孩子的家庭有6000个,有3个孩子的家庭有3000个。
将此城市中任一个家庭中孩子的数目看作一个随机变量,记为 X X X。它可能的取值有 0 、 1 、 2 、 3 0、1、2、3 0、1、2、3。其中, X X X取0的概率为0.01,取1的概率为0.9,取2的概率为0.06,取3的概率为0.03。
则它的数学期望 E ( X ) = 0 × 0.01 + 1 × 0.9 + 2 × 0.06 + 3 × 0.03 = 1.11 E(X)=0×0.01+1×0.9+2×0.06+3×0.03=1.11 E(X)\=0×0.01+1×0.9+2×0.06+3×0.03\=1.11,即此城市一个家庭平均有小孩1.1个,当然要按整数计算,约等于2个。
范例精讲
例1 小明要去南美洲旅游,一共乘坐三趟航班才能达到目的地,其中第1个航班的准点概率是0.9,第2个航班的准点概率是0.8,第3个航班的准点概率是0.9.如果存在第i个(i=1,2)航班晚点,第i+1个航班准点,则小明将赶不上第i+1个航班,旅行失败;除了这种情况,其他情况下旅行都能成功。请问小明此旅行成功的概率是( )。
A.0.8 B.0.648 C.0.72 D.0.74
解析:倒着算更容易一些,找询问事件的对立事件,即旅行失败的概率,失败的情况有:
- 一晚二准三任意,概率为 0.1 × 0.8 × 1 0.1×0.8×1 0.1×0.8×1
- 一任意二晚三准,概率为 1 × 0.2 × 0.9 1×0.2×0.9 1×0.2×0.9
P ( 失败的概率 ) = 0.1 × 0.8 + 0.2 × 0.9 = 0.26 P(失败的概率)=0.1×0.8+0.2×0.9=0.26 P(失败的概率)\=0.1×0.8+0.2×0.9\=0.26
P ( 成功的概率 ) = 1 − 0.26 = 0.74 P(成功的概率)=1-0.26=0.74 P(成功的概率)\=1−0.26\=0.74
例2 一家四口人,至少两个人的生日属于同一月份的概率是( )。(假定每个人的生日属于每个月份的概率相同且不同人之间相互独立)
A.1/12 B.0.1/144 C.41/96 D.3/4
解析:还是倒着算,“至少两个人的生日属于同一月份”的对立事件是“所有人的生日都不在同一月份”。
第一个人有12种选择,第二个人有11种,第三个人有10种,第四个人有9种。
P ( 都不在同一月份 ) = 12 × 11 × 10 × 9 / ( 12 × 12 × 12 × 12 ) = 55 / 96 P(都不在同一月份)=12×11×10×9/(12×12×12×12)=55/96 P(都不在同一月份)\=12×11×10×9/(12×12×12×12)\=55/96
P ( 至少两个人的生日属于同一月份 ) = 1 − 55 / 96 = 41 / 96 P(至少两个人的生日属于同一月份)=1-55/96=41/96 P(至少两个人的生日属于同一月份)\=1−55/96\=41/96
赛题训练
- 假设一台抽奖机中有红、蓝两色的球,任意时刻按下抽奖按钮,都会等概率获得红球或蓝球之一。有足够多的人每人都用这台抽奖机抽奖,假如他们的策略均为:抽中蓝球则继续抽奖,抽中红球则停止。最后每个人都把自己获得的所有球放到一个大箱子里,最终大箱子里的红球与蓝球的比例接近于( )。
A.1:2 B.2:1 C.1:3 D.1:1 - 欢乐喷球:儿童游乐场有个游戏叫“欢乐喷球”,正方形场地中心能不断喷出彩色乒乓球,以场地中心为圆心还有一 圆形轨道,轨道上有一列小火车在匀速运动,火车有六节车厢。
假设乒乓球等概率落到正方形场地的每个地点,包括火车车厢。小朋友玩这个游戏时,只能坐在同一个火车车厢里,可以在自己的车厢里捡落在该车厢内的所有乒乓球,每个人每次游戏有三分钟时间,则一个小朋友独自玩一次游戏期望可以得到( )个乒乓球。假设乒乓球喷出的速度为 2个/秒,每节车厢的面积是整个场地面积的 1/20。
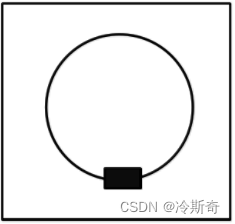
A.60 B.108 C.18 D.20 - 在一条长度为1的线段上随机取两个点,则以这两个点为端点的线段的期望长度是( )。
A.1/2 B.1/3 C.2/3 D.3/5