本文章由 WyOJ Shojo 从洛谷专栏拉取,原发布时间为 2024-01-29 15:46:21
- 注: 2024.1.31 更新 tarjan 做法
倍增做法
题目
这道题是一道模板题, 很适合来练练手。
建树+dfs:
建树就不多说了, 你可以把它当成一个图来建, 用动态数组和结构体都可以。
但是不管用哪种方法, 都需要用 dfs 来辅助, 确认它们的父子关系, 详细解释看代码。
dfs 代码:
void dfs(int now,int step){
maxdep=max(maxdep,step);\/\/maxdep表示这棵树的深度
vis[now]=true;\/\/打访问标记
dep[now]=step;\/\/记录该点的深度
for(int i=0;i<g[now].size();i++)\/\/枚举
if(!vis[g[now][i]]){
fath[g[now][i]][0]=now;\/\/记录父亲
\/\/这里fath[i][0]表示 i 点的父亲,fath[i][1]表示其父亲的父亲
\/\/以此类推
dfs(g[now][i],step+1);\/\/继续dfs
}
return;\/\/结束
}
确认祖先:
这里, 确认祖先的思想与 ST 表很接近, 都是先枚举 $j$, 这道题就是 ST 表的模板题。
那么我们思考一下, 例如这棵树:
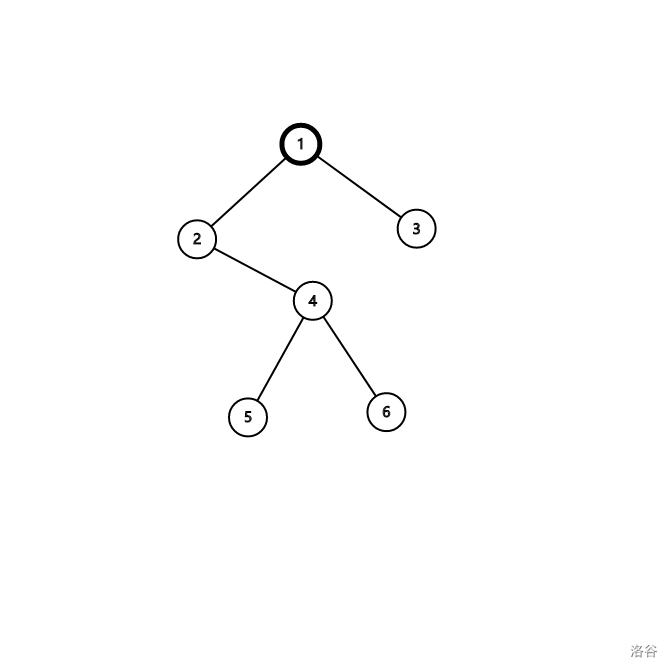
可以看到, 这棵树上的 $5$ 的父亲是 $4$,$4$ 的父亲是 $2$,$2$ 就是 $5$ 的父亲的父亲。(废话)
所以我们得到:
$$fath_{i,j}=fath_{fath_{i,j-1},j-1}(1\le i\le n,1\le j\le \log_2(maxdep-1))$$
那么, 我们可以提前维护一个数组来维护 $\log_2(x)(1\le x\le n)$, 我给它命名为 $lg$。
维护 $lg$ 代码:
lg[1]=0;
for(int i=2;i<=n;i++) lg[i]=lg[i>>1]+1;
维护 $fath$ 代码:
for(int len=1;len<=lg[maxdep-1];len++)
for(int i=1;i<=n;i++) fath[i][len]=fath[fath[i][len-1]][len-1];
终于要 LCA 了!
暴力跳:
LCA 的第一步是要保证两个点的深度相同, 不相同则让更深的那个点跳到与较浅的那个点一样深, 再让两个点一起向上跳, 直到两点重合。
说起来轻松, 但若这个点特别深, 难道要一层一层的向上跳吗?
正解:
那么, 我们假如这个点要跳 $19$ 层, 对 $(19)_{10}$ 进行二进制拆分是 $(010011)_2$。
我们发现, 实际就是下面这样一个过程:
- 判断剩余要跳的层数的二进制的第 $i$ 位是否是 $1$(实际上就是在判断往上跳 $2^i$ 层后有没有超过另一个点), 如果是 $1$, 转至第 $2$ 步, 否则, 转至第 $3$ 步。
- 向上跳 $2^i$ 层, 并转至第 $3$ 步。
- $i$ 减一(就是要判断下一位), 并判断两点深度是否相同, 若相同, 则退出循环, 否则, 转至第 $1$ 步。
在两点同时跳时, 也是这样一个过程。
代码:
for(int i=1;i<=m;i++){
u=read();
v=read();
if(dep[u]<dep[v]) swap(u,v);\/\/保证u的层数大于等于v的层数
for(int j=lg[maxdep-1];j>=0&&dep[u]>dep[v];j--)
if(dep[fath[u][j]]>=dep[v]) u=fath[u][j];\/\/让u向上跳
if(u==v){\/\/特判
write(u);
putchar('\n');
continue;
}
for(int j=lg[dep[u]];j>=0;j--)\/\/让两点同时向上跳
if(fath[u][j]!=fath[v][j]){
u=fath[u][j];
v=fath[v][j];
}
write(fath[u][0]);
putchar('\n');
}
总代码:
#include<bits\/stdc++.h>
#define N 500005
#define int long long
using namespace std;
vector<int>g[N];
int n,m,s,dep[N],fath[N][30],u,v,maxdep,lg[N];
bool vis[N];
int read(){
int f=1,x=0;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=(x<<1)+(x<<3)+(ch^48);
ch=getchar();
}
return f*x;
}
void write(int x){
if(x<0) x=-x;
if(x>=10) write(x\/10);
putchar(x%10^48);
}
void dfs(int now,int step){
maxdep=max(maxdep,step);
vis[now]=true;
dep[now]=step;
for(int i=0;i<g[now].size();i++)
if(!vis[g[now][i]]){
fath[g[now][i]][0]=now;
dfs(g[now][i],step+1);
}
return;
}
signed main(){
n=read();
m=read();
s=read();
lg[1]=0;
for(int i=2;i<=n;i++) lg[i]=lg[i>>1]+1;
for(int i=1;i<n;i++){
u=read();
v=read();
g[u].push_back(v);
g[v].push_back(u);
}
dfs(s,1);
for(int len=1;len<=lg[maxdep-1];len++)
for(int i=1;i<=n;i++) fath[i][len]=fath[fath[i][len-1]][len-1];
for(int i=1;i<=m;i++){
u=read();
v=read();
if(dep[u]<dep[v]) swap(u,v);
for(int j=lg[maxdep-1];j>=0&&dep[u]>dep[v];j--)
if(dep[fath[u][j]]>=dep[v]) u=fath[u][j];
if(u==v){
write(u);
putchar('\n');
continue;
}
for(int j=lg[dep[u]];j>=0;j--)
if(fath[u][j]!=fath[v][j]){
u=fath[u][j];
v=fath[v][j];
}
write(fath[u][0]);
putchar('\n');
}
return 0;
}
tarjan 上的 dfs:
当然, 倍增有些人可能觉得有些难, 那么我再来补一下 tarjan 做法。
简介 tarjan
先放个图:
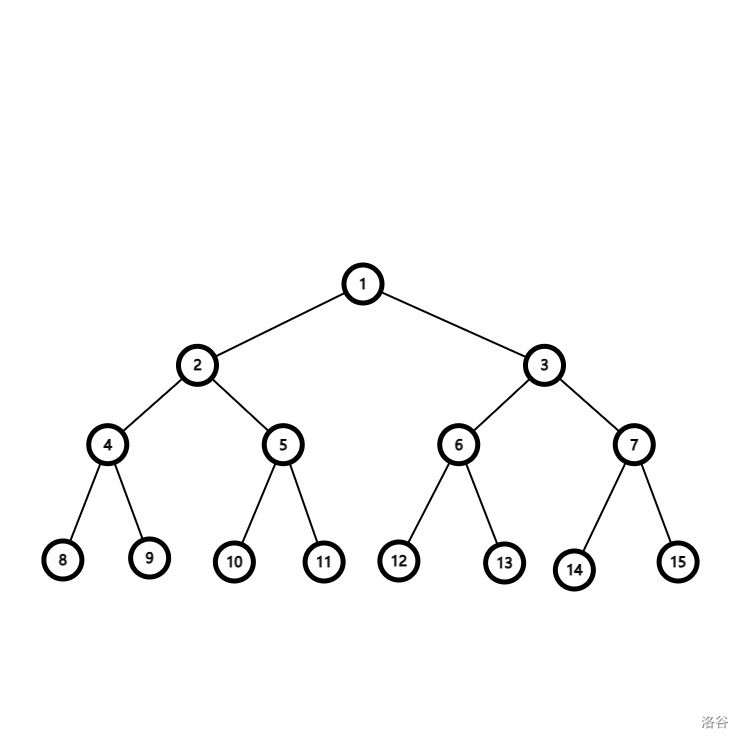 假设我要求 $4$ 和 $7$,$4$ 和 $10$ 的 LCA, 那么我们再建个图。
假设我要求 $4$ 和 $7$,$4$ 和 $10$ 的 LCA, 那么我们再建个图。
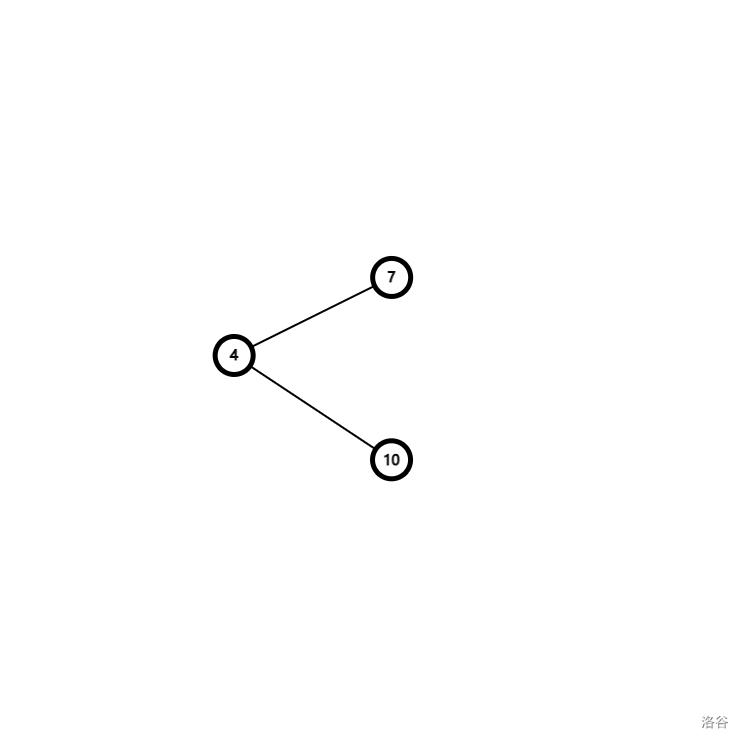 然后我们进行 dfs, 搜到哪里就在哪里打访问标记, 并确定父子关系。
然后我们进行 dfs, 搜到哪里就在哪里打访问标记, 并确定父子关系。
等到遍历完成后, 再来到第二个图, 按照第一个图的父子关系进行查找。
详细流程如下:
建图
第一步还是建图, 不过这次我用结构体再建一遍。
代码如下:
void add(int x,int y){\/\/原图
t[++tot].to=y;
t[tot].nxt=head[x];
head[x]=tot;
return;
}
void addx(int x,int y){\/\/节点关系建图
tx[++totx].to=y;
tx[totx].nxt=headx[x];
headx[x]=totx;
return;
}
\/\/以上均为模板,不再赘述
\/\/主程序内调用
for(int i=1;i<n;i++){
u=read();
v=read();\/\/原图
add(u,v);
add(v,u);
}
for(int i=1;i<=m;i++){
u=read();
v=read();
addx(u,v);\/\/节点之间建图
addx(v,u);\/\/注意,单向建图与双向建图会影响后面的代码
}
tarjan 操作
这里将结构体 dfs 模板修改一下即可。
详细解释看代码:
void tarjan(int now){
vis[now]=true;\/\/打访问标记,还是dfs的套路
for(int i=head[now];i;i=t[i].nxt){\/\/原图dfs
int ta=t[i].to;
if(vis[ta]) continue;\/\/不重复查找
tarjan(ta);\/\/递归调用
fa[ta]=now;\/\/修改父子关系
}
for(int i=headx[now];i;i=tx[i].nxt){\/\/结点关系dfs
int ta=tx[i].to;
if(vis[ta]){
lca[i]=find(ta);\/\/查找函数代码在下面
if(i&1) lca[i+1]=lca[i];\/\/这里就是刚刚说的不一样, 由于双向建边导致需要存两次, 不然会出错
else lca[i-1]=lca[i];
}
}
return;\/\/结束
}
find 函数代码:
int find(int u){
if(u!=fa[u]) fa[u]=find(fa[u]);
return fa[u];
}\/\/标准find函数
输出就不用看了吧
总代码:
#include<bits\/stdc++.h>
#define N 500005
#define int long long
using namespace std;
struct trees{
int to,nxt;
}t[N<<1],tx[N<<1];
int n,m,s,u,v,head[N<<1],tot,headx[N<<1],totx,fa[N<<1],lca[N<<1];
bool vis[N<<1];
int read(){
int f=1,x=0;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-') f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=(x<<1)+(x<<3)+(ch^48);
ch=getchar();
}
return f*x;
}
void write(int x){
if(x<0) x=-x;
if(x>=10) write(x\/10);
putchar(x%10^48);
}
void add(int x,int y){
t[++tot].to=y;
t[tot].nxt=head[x];
head[x]=tot;
return;
}
void addx(int x,int y){
tx[++totx].to=y;
tx[totx].nxt=headx[x];
headx[x]=totx;
return;
}
int find(int u){
if(u!=fa[u]) fa[u]=find(fa[u]);
return fa[u];
}
void tarjan(int now){
vis[now]=true;
for(int i=head[now];i;i=t[i].nxt){
int ta=t[i].to;
if(vis[ta]) continue;
tarjan(ta);
fa[ta]=now;
}
for(int i=headx[now];i;i=tx[i].nxt){
int ta=tx[i].to;
if(vis[ta]){
lca[i]=find(ta);
if(i&1) lca[i+1]=lca[i];
else lca[i-1]=lca[i];
}
}
return;
}
signed main(){
n=read();
m=read();
s=read();
for(int i=1;i<=n;i++) fa[i]=i;
for(int i=1;i<n;i++){
u=read();
v=read();
add(u,v);
add(v,u);
}
for(int i=1;i<=m;i++){
u=read();
v=read();
addx(u,v);
addx(v,u);
}
tarjan(s);
for(int i=1;i<=m;i++){
write(lca[i<<1]);
putchar('\n');
}
return 0;
}
两者对比
tarjan 时间复杂度为 $O(n+m)$, 而倍增为 $O(n\log_2n)$,tarjan 更优。
但其致命缺陷也很明显, 就是无法修改。