欢迎参加 WYOJ2026 愚人节比赛!
这场比赛将包含若干道【】题,Rated,不设置等级分上限,不分 Div。
等级分变动范围是 $[-1000,1000]$,如果不参加比赛,你将会得到 【封号】的处罚,请务必参加。
如果你参加了比赛,RYP 将会免费将 WYOJ 的所有权赠送给你,只是 RYP 保留 24h 使用权。
欢迎参加 WYOJ2026 愚人节比赛!
这场比赛将包含若干道【】题,Rated,不设置等级分上限,不分 Div。
等级分变动范围是 $[-1000,1000]$,如果不参加比赛,你将会得到 【封号】的处罚,请务必参加。
如果你参加了比赛,RYP 将会免费将 WYOJ 的所有权赠送给你,只是 RYP 保留 24h 使用权。
我打算把 WyOJ 设计成可以给大家进行自习的系统。自习是很重要的,也占据了大部分 OIer 的大部分在役时光。所以如何利用好自习时间是很重要的。
另外,我们也需要给教练提供一个可用于训练的平台。
具体地,我打算做一个类似 Duel 但超越 Duel 的东西。传统的 Duel 是随机题目,并且双人。我们可以做多人,并且根据 AI 以及推荐算法来精准推荐一些适合这些选手的题目。我们可以根据每个人擅长的题目,推荐每个人的舒适区各一道或者更少,以此让每个人不至于无题可做的同时,可以做一些自己不一定很擅长的题目。
另外,我们可以根据每次 Duel 的结果,来更新每一个人的面孔。Duel 是比普通做题记录更珍贵的资源,因为在 Duel 中我们可以知道每个人做每道题的时间、尝试次数等等参数。
我们怎么实现呢?
首先要实现一个远端评测系统。也即,利用 HK 的云服务器将提交请求转发到洛谷,并跟踪结果。另外我们可以利用 HK 的服务器爬取题解并在本地用自己的显卡来进行分析。
没有更多难写的东西。
等到大周以及清明尽量实现一下。我觉得没有那么难。
具体实现:
相似题目推荐是基本中的基本。因为这个玩意需要一定算力,因此把他做成异步的,后面用一个 FastAPI,用 frp 之类的反代到一个子域名。
需要实现什么功能呢?
给定用户,根据他通过的题目,进行匹配,得到相似题目,并按照难度召回
给定关键词,根据关键词匹配出相似题目,并按难度筛选或者召回
然后就是前端。前端可以做在首页,这样比较帅气。按一个按钮就自动搜索相似题目。
如前。可以用 HK 的服务器甚至是集群,用个 Redis 或者之类的简单队列维护一下,细节比较多,尤其是和 UOJ 那堆写的没法说好的评测系统结合的时候应该会不怎么舒服。最简单的方式是,提交到数据库,然后本地再跑一个消费者推送到远端的 Redis。
这个没那么难写,但是应该没法融合到原来的比赛架构里头,这玩意儿简直是屎山。最好是新开一个类似比赛的页面。
-- upd 20260407
清明摆了,没有怎么写。
另外我还需要一定的时间来更深地研究一下深度学习还有推荐系统那套架构。现在写,只能做出点儿小学生 demo 来。聊胜于无。
WyOJ 的前端实在是太丑了,不得不好好重新设计一下。于是我不得不去学前端。其实我也挺想学的,感觉设计这种东西应该很有意思。
我本来从来没有记笔记的习惯的,但是感觉前端这些东西实在是太杂了,不记根本跟没学差不多。所以记一下。
我问了问 DS 有啥需要学的,DS 说:
一、CSS 基础核心(必须滚瓜烂熟)
基础选择器:标签、类、ID、通配符、属性选择器。
关系选择器:后代、子代、相邻兄弟、通用兄弟。
伪类与伪元素::hover、:focus、:nth-child()、::before、::after。
优先级计算:内联 > ID > 类/伪类 > 标签,以及 !important 的影响。
组成:content、padding、border、margin。
两种盒模型:box-sizing: content-box(默认)与 border-box(推荐,让宽度包含 padding 和 border)。
边距折叠:相邻块级元素的上下外边距会合并。
文本与字体:font-family、font-size、font-weight、line-height、text-align、color。
背景与边框:background-color、background-image、border、border-radius。
尺寸与间距:width、height、padding、margin。
二、布局核心(如何摆放元素)
块级元素独占一行,行内元素在一行内排列。
通过 display 改变元素类型:block、inline、inline-block。
让元素向左或向右浮动,文字环绕。需要清除浮动(clearfix)避免父容器高度塌陷。
static:默认。
relative:相对自身原位置偏移,不脱离文档流。
absolute:脱离文档流,相对于最近的非 static 祖先定位。
fixed:相对于视口定位。
sticky:粘性定位,在滚动到阈值时表现像 fixed。
核心概念:容器(display: flex)、项目、主轴、交叉轴。
常用属性:
容器:flex-direction、flex-wrap、justify-content、align-items、align-content。
项目:flex-grow、flex-shrink、flex-basis、align-self。
适用场景:导航栏、卡片列表、表单对齐、垂直居中。
核心概念:容器(display: grid)、行、列、单元格、网格线。
常用属性:
容器:grid-template-columns、grid-template-rows、gap、grid-template-areas。
项目:grid-column、grid-row、grid-area。
适用场景:复杂页面布局、图片墙、仪表盘。
媒体查询:@media (max-width: 768px) { ... }。
视口单位:vw、vh、vmin、vmax。
弹性单位:rem(相对于根元素字体)、em(相对于父元素字体)。
响应式图片:srcset、sizes、picture 元素。
容器查询(进阶):根据父容器大小调整内部样式。
三、设计转化:从脑中的设计到代码 1. 视觉分解法
看到一个设计(或自己脑中的画面),按以下顺序拆解:
大结构:整个页面分几块?头部、主体、底部?主体是几列?用 Grid 还是 Flex?
模块划分:每个区块内部有哪些组件?如卡片、列表、表单。
细节属性:每个组件的颜色、字体、间距、边框、阴影。
先结构后样式:先用 HTML 搭建骨架(只考虑标签语义和嵌套),再写 CSS。
从外到内:先定好大容器的大小和位置,再处理内部元素。
利用浏览器调试:随时在开发者工具里修改样式,实时看效果,边试边调。
卡片:border-radius、box-shadow、padding、display: flex(垂直或水平排列内部)。
导航栏:display: flex,justify-content: space-between,子项 padding。
表单:display: grid 或 flex 对齐标签和输入框。
列表:list-style: none,padding,border-bottom 分隔。
按钮:padding、border-radius、background-color、:hover 变色。
有时间的话可以讲一下光速幂当个拓展,但没有什么实际意义。
我现在已经基本摸清了洛谷的前后端套路。我们可以直接在 WyOJ 交洛谷的题目了。
具体做法是:
新增一个 /rp/{pid} 的路由,专门给远程题目(Remote Problem,非常好的缩写)使用
/rp/{pid} 是有缓存的。缓存过的题目(题面)直接渲染,没有缓存的放入队列中等待缓存,前端自动定时刷新。
/rp/{pid} 模拟传统的 /problem/{pid},可以提交题目,但是需要先绑定洛谷账号(uid 与 clientid)。
我觉得远程提交列表还是和本地提交列表分开比较好。那就用一个 /rs/{rid},并放入队列中,等待定期爬取。
除了爬取 /record/{rid},我们还可以直接爬 /record/list?uid={uid},主动观察用户完成了什么题目。
博客现在已经爬了,但是没有做定期更新。之后干脆直接把动态也爬过来,和 WyOJ 未来可能做的动态系统一融合。
这样一搞机房甚至可以直接白名单 WyOJ 了。机房的学弟学妹可不要怪我封了你们颓的路。
如题!
大家可以推自己喜欢的歌。
因为大带宽的服务器太贵了(一年 400+),所以暂时搞不了图床。请用自己喜欢的图床上传封面。
当然,你可以传除了封面以外的东西,适度的娱乐是被鼓励的。
严禁上传违禁内容。管理员有随时删除任何数据的权利。
作者:_ryp_
山东提供的是 Windows + NOI Linux 虚拟机。使用 Linux 主要是为了测试编译、时间与内存限制。
首先打开终端。按 Super 键(Windows 键)打开搜索框,搜索 terminal 并运行,打开的是一个深紫色背景窗口。
把文件复制到主文件夹,类比 Windows 中的用户目录。在终端中,可以用 ls 命令查看当前文件夹内有哪些文件,检查代码是否复制错了地方。
我在我的工作目录下输入 ls,会得到类似这样的信息:

蓝色的是目录、绿色的是可执行文件,白色的是普通文件。因为我的系统是日用的,所以和考场中有的文件夹不同。一般的,看到有 Documents、Desktop,或者 文档、桌面 等文件夹,就是主目录。
要编译 a.cpp ,可以输入命令:
g++ a.cpp -o a -Wall -Wextra -std=c++14 -O2 -g
其中,g++ 是必须的;a.cpp 是文件名,可以更改;-o a 是指定可执行文件名,Linux 下的可执行文件是不带后缀名的;-Wall -Wextra 是打开所有警告;-std=c++14 是指定标准;-O2 是打开优化,可以删掉;-g 是打开调试符号,不会使用调试器的可以忽略。
编译后,可以用 ls 命令查看是否多出来了 a 文件,即指定的可执行文件名。随后,使用 ./a 命令可以运行这个程序。
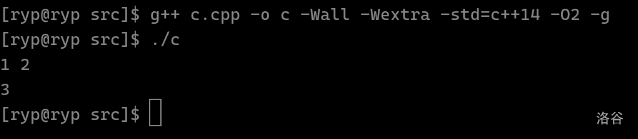
以 A + B 为例。我这里的源代码名为 c.cpp,我希望它编译成 c。使用如下命令并运行、输入,得到期望输出:
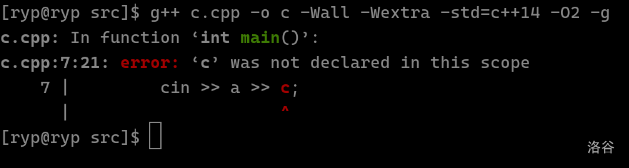
如果运行编译命令后出现额外信息,是编译错误或者警告,具体和 Dev C++ 下栏中显示的错误相同。比如我将 cin >> a >> b 误写作 cin >> a >> c,会得到:
我们看看 RE 会怎么样。如下图:
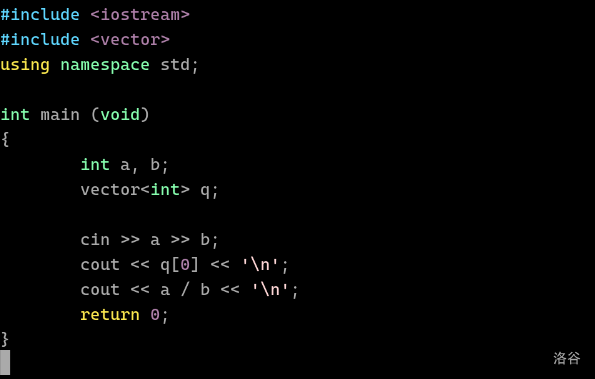
我们故意 RE。

Segmentation fault,或者 段错误,是内存访问越界,或者 STL 容器的使用出错。删掉 cout << q[0] << '\n',看看除零:

会显示 Floating point exception,或 浮点错误 等。有的 STL 错误还会附带 STL 的错误信息,这点和 Windows 是大体一致的。
测试程序用时,可以用 time 或者 /bin/time 命令,后者显示的更多,不会的可以只用前者。具体的,使用 time ./a 命令运行并测速,其他的和不测速时一样。由于用键盘输入的时间计入总时,所以最好使用文件输入。
我们以测速 ./c 为例。这里我用了文件输入输出。
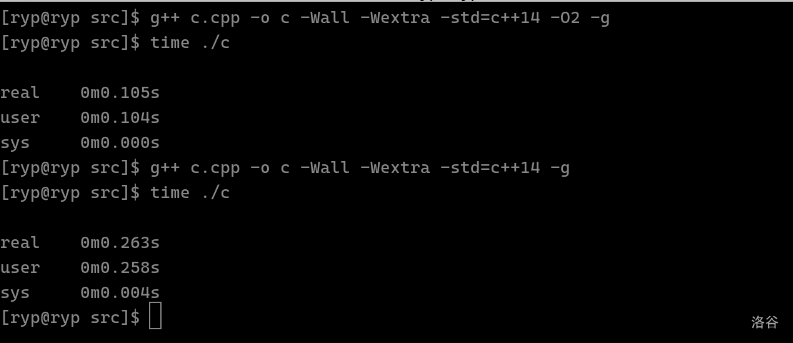
这里我测试了两次,分别是同一份源代码,O2 与不开启 O2 的速度。测评时间是 user 行后面的。这里是 0.104s(O2)与 0.258s(无优化)。
内存分为静态内存和动态的。静态的是直接开的全局数组、变量、还有代码本身的长度。动态的如 vector、栈等 STL 容器。
静态内存可以用 size 命令测试。

找到输出的 dec,也就是倒数第三个,6408903,就是静态内存占用,单位是字节。除以 1048576 得到以 MB 为单位的静态内存。
动态内存不好直接测试,但是可以通过限制总内存使用量来判断是否超过内存限制。具体命令是:ulimit -v X,其中 X 是内存限制,单位是 KB。或者,可以使用 ulimit -v $((X * 1024)),X 同样是内存限制,但单位是 MB。记不住可以计算器换算后用前者。
以下面程序为例。
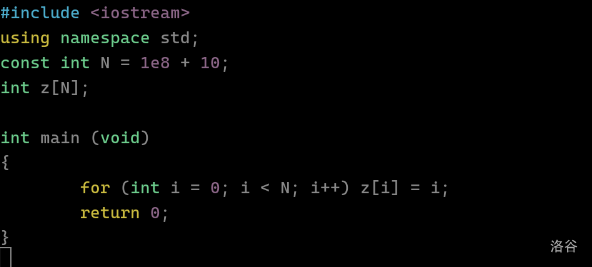
笔算可知内存占用是大概是 380MB。我们把内存放到 256MB:
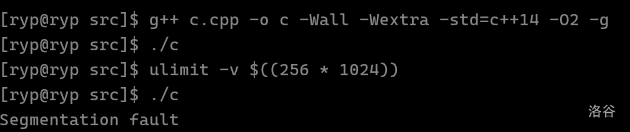
ulimit 命令前,执行是正常的。执行 ulimit 命令后,我们发现出现 RE。这是因为 MLE 了。
注意内存限制如果过小,会导致终端的正常任务无法执行。这时打开一个新终端即可。
import os
import time
import subprocess
import sys
import argparse
import time
from openai import OpenAI
def fetch_generator(statement, model, maxtokens):
APIKEY = os.environ.get('DEEPSEEK_API_KEY')
if not APIKEY:
raise Exception('需要设置 DEEPSEEK_API_KEY 环境变量')
client = OpenAI(
api_key=APIKEY,
base_url='https://api.deepseek.com')
start_time = time.time()
msgs = [{ 'role': 'user', 'content':
"""
请根据以下信息学竞赛题目生成数据生成器。只输出 gen.py 代码。
要求:
1. 解析题目中的输入格式、数据范围和子任务划分
2. 创建 data/ 目录并生成所有 .in 文件
3. 数据严格符合题目约束
4. 使用合理的数据梯度,包含边界情况
5. 数据文件名一定为 'data{编号}.in',编号不含前导零
6. 没有子任务的,数据文件直接放在 data/ 下;有子任务的,为每个子任务创建 subtask{编号}/ 目录,把数据文件移动到对应的子任务目录中
7. 数据点在 10 到 20 个内
8. 务必确保你给出的数据是正确的!先列出生成器的设计思路和待满足的所有约束条件,确认无误后再生成完整代码
输出只包含可以直接运行的 gen.py 的代码,无其他内容。
题目描述:""" + statement}]
resp = client.chat.completions.create(
model=model,
messages=msgs,
stream=False,
temperature=0.0,
max_tokens=maxtokens)
response = resp.choices[0].message.content
tokens = resp.usage.total_tokens
if response.startswith('```python'):
response = response[9:-3]
return (response, tokens, time.time() - start_time)
def execute(s):
print('正在执行命令:', s)
try:
subprocess.run(['bash', '-c', s], check=True, timeout=40)
except subprocess.CalledProcessError as e:
raise Exception('命令执行错误')
except subprocess.TimeoutExpired:
raise Exception('命令执行超时(20s)')
def generate_in():
# 其实应该用个沙盒比较安全,但是我懒得写了。可以最后扔到容器里头跑。
execute('python gen.py')
def flatten_data():
execute('find -type f | xargs -I {} mv -n {} . || true')
execute('rmdir subtask* || true')
def run_std():
if not os.path.exists('../std.cpp'):
raise Exception('未找到 std.cpp')
execute('g++ ../std.cpp -o std -Wall -Wextra -O2 -std=c++14')
for i in os.listdir():
if not i.endswith('.in'):
print(f'警告:未知文件 {i}')
continue
out = i[:-2] + 'ans'
execute(f'./std < {i} > {out}')
execute('rm std')
def gen_problem_conf(time, mem):
execute(f'python ../autoconf.py {time} {mem}')
def compress_data():
execute('zip ../data.zip -r .')
def cleanup():
os.chdir('..')
execute('rm -r data/')
def pretty_size(d):
if d < 1024:
return f'{d}'
if d < 1048576:
return f'{d/1024:.2f} KB'
return f'{d/1048576:.2f} MB'
if __name__ == '__main__':
start_time = time.time()
parser = argparse.ArgumentParser()
parser.add_argument('statement', help='题面文件')
parser.add_argument('--model', type=str, default='deepseek-reasoner', help='使用的模型(默认为 deepseek-reaonser,可以改为 deepseek-chat)')
parser.add_argument('--maxtokens', type=int, default=50000, help='token 上限(默认为 50000)')
parser.add_argument('--time', type=int, default=1, help='时间限制(秒,默认为 1)')
parser.add_argument('--mem', type=int, default=256, help='空间限制(MB,默认为 256)')
parser.add_argument('--offline', help='不生成新的 gen.py', action='store_true')
args = parser.parse_args()
if os.path.exists('data'):
print('正在清空已有的 data 目录')
execute('rm -r data')
if os.path.exists('data.zip'):
print('删除已存在的 data.zip')
execute('rm data.zip')
tokens = 0
with open(args.statement) as f:
if not args.offline:
print(f'正在请求 {args.model},token 上限为 {args.maxtokens} 个')
resp, tokens, duration = fetch_generator(f.read(), args.model, args.maxtokens)
with open('gen.py', 'w') as fw:
fw.write(resp)
print(f'--- tokens: {tokens}, time cost: {duration:.6f} seconds')
else:
if not os.path.exists('gen.py'):
raise Exception('离线模式下必须提供已有的 gen.py')
print('(离线模式)')
generate_in()
os.chdir('data')
gen_problem_conf(args.time, args.mem)
# run_std 需要一个扁平的目录,也就是所有文件放在 data/ 下,而 autoconf.py 不要求这么做
flatten_data()
run_std()
compress_data()
cleanup()
prettysize = pretty_size(os.path.getsize('data.zip'))
print(f'已生成 data.zip({prettysize}),耗时 {(time.time() - start_time):.2f} 秒,消耗 {tokens} 个 token')我需要一个用来执行 321 备份的系统。同时我发现我好几个朋友都在考虑数据备份,所以就干脆写一个。
由于我那个腾讯云服务器带宽非常小,所以我整了一台 50Mbps 的新内网穿透隧道,用来上传数据。
具体的逻辑是:前端发送 POST 从 PHP 那获取一个密码,密码是用密钥加密的有关事务的信息,比如最大数据大小,同步时用的策略等,还可以用来保证用户是已经登录的。因为用来传输的服务端和 PHP 的服务端是分离的,要做数据同步太麻烦。
然后另一个服务端就得到数据,把数据保存到本地,并同时维护备份策略,然后后台的备份服务器来定期推送到存储服务器。
挺简单的架构,写着玩了。
-- upd 2026/1/1 写了个头,一直没写完。
WyOJ 面向的主要用户是谁?
首先是 wfyz 的同学,WyOJ 的性质首先是校内的 OJ。
其次,是水平高的,还是水平低的?
目前为止 WyOJ 的主要用户是水平尚可的初二到高二同学,主要的用处是来打模拟赛。虽然说理论上也有补题的作用,但是补的人不是很多。
高水平的同学会上类似 hba 或者现在的 LCA 那里去集训。所以 WyOJ 应该面向低到中等偏上水平的同学。
这部分同学的特点是什么?大部分的算法已经学习完成,但是有缺陷,有短板。WyOJ 应该能给他们提供一个平台,让他们可以快速认清自己的短板,快速补齐。
这需要什么?首先需要让他们知道自己有短板、短板在哪里。其次需要让他们知道怎么补,怎么做题,做哪些题。
这其实很重要。我在役时间只有一年。前大半年我基本上都是在学算法,到第二年的四五月份左右,NOIP 级的算法我早就掌握完了,还学了一堆屁用没有的 ds。
直到六七月模拟赛开始多起来,我才逐渐意识到我的比赛成绩与水平非常之低。七八月我去了 mx 集训,在那里我可以说打了一百万场模拟赛,但是回来之后似乎提升并没有想象的那么多。
我观察到这似乎是一个非常共同的问题。
总结一下这个问题是什么呢:
只接受过集训,针对性的训练比较少,害怕打模拟赛
智力在线,算法点满了,但不均衡
通过模拟赛意识到自己有大问题,但是靠自己不太清楚怎么补,或者是就算找到了题单,也做不下去
比如说,我早就认识到我的贪心是个大问题,我找了一堆贪心的题单,包括 CF 的 ABCD 这种难度的题目去训练。
但是问题在哪里:做不出来的题目还是做不出来,能做出来的题目本来就能做出来。训练效果为零。
最终我的 NOIP 在贪心上撞死了。我想,如果我在役时把贪心给补好,也许结果会很不一样。
但我已经退役很久了。我希望能让以后的同学们不再受类似的问题困扰。
所以说,怎么办?
WyOJ 应该提供一个专题训练的功能。
具体就是用大模型。
互联网的优点就是大量的数据,这也是他的缺点,我们要做的就是选出我们要的那些数据来。
我想要的数据是优质的、有中文题面、带题解的题目。我能想到的是洛谷爬的 Codeforces、AtCoder 的题目。理由如下:
有中文题面,好做
质量有一定保证
有题解,虽然数量参差不齐但是可以选择题解数量多的
CF 提供了一点 API,但是似乎没有提供读取题面的 API,看来他不怎么希望能让别人爬他的题面。At 的 API 似乎也差不多。
用洛谷的好处是我已经会了,WyOJ Shojo 可以打个样。Shojo 这个名字太二了,换成 Maid 还好点儿。
然后我们可以用大模型去阅读这些题解,得到对这个题的一个大概认识。
我还没有认真学好深度学习,虽然整了本书,但只看到 CNN,离着 LLM 还远。
然后通过一些类似 IOI 赛制的比赛来测试每个人的能力,再不断测试出每个人各项能力的大致分数区间,随后针对性推荐题目。
这是个推荐网络,推荐网络里头似乎有很多有意思的算法,深度学习里头也有很多有意思的算法。
这个草稿还相当简略,但是想法已经成型了。
我非常期待这套系统能早日成功,帮助像曾经的我那样的同学们能够获得更好的分数。